CSVの仕様
まず重要な点は、「CSVは、ファイルを読んで、1行ずつ、単純に「,」で分割していけばいいってものではない」ということである。
CSVの標準的な仕様として、現在RFC4180が定義されている。
http://www.kasai.fm/wiki/rfc4180jp
http://www.ietf.org/rfc/rfc4180.txt
しかしながら、これは2005年10月に公開された後追いであり、おそらく、実際、それぞれの現場で使っている物と異なる箇所があると思われる。
この仕様で述べている主な特徴は次の通りになる。
・各レコードは、改行(CRLF)を区切りとする
・ファイル末尾のレコードの終端には、改行があってもなくてもいい。
・ファイルの先頭にはヘッダ行が存在してもいいしなくてもいい。
・各行とヘッダはコンマで区切られたフィールドを持つ。
・フィールドの数は、ファイル全体を通じて同一であるべき。
・最後のフィールドは、コンマで終わってはいけない。
・各フィールドはダブルクォーテーションで囲んでもいいし、囲まなくてもいい。
・改行を含むフィールドはダブルクォーテーションで囲むべき。
・ダブルクォーテーションを含むフィールドはダブルクォーテーションで囲み、フィールド中のダブルクォーテーションの前にダブルクォーテーションを付与する。
xxx,"test""test"各プログラミング言語での実装例
各プログラミング言語で次のCSVを操作する例を示す。
今回のサンプルでは次のCSVファイルがどのように取り込めるか検証する。
test1.csv 一般的なCSVの例
ジャック,12,戦士,説明1
バーン,17,騎士,説明2
マァム,15,僧侶,説明3test2.csv 1行目がコメントで、フィールドに改行、ダブルクォーテーション、コンマが混入している場合
# 名前,歳,クラス,説明に(",)を入れる
"ジャック","12","戦士",",や""が入力可能"
"バーン","17","騎士","説明2
改行を行う"
"マァム","15","僧侶","説明3"test3.csv 空行が存在する例
# 空行の扱い
"ジャック","12","戦士",",や""が入力可能"
"バーン","17","騎士","説明2
ダブルクォート中に空の改行がある場合"
# 途中のコメント
"マァム","15","僧侶","説明3"test4.csv 各レコードの列数が異なる例
# 列の数が異なる場合
"ジャック","12"
"バーン"
"マァム","15","僧侶","説明3"
.NET(C#)での実装例
TextFieldParserを使用する例
「Microsoft.VisualBasic」を参照することで使用できるTextFieldを用いて解析する例を以下に示す。
CSV読み込みのサンプル
using System;
using System.Collections.Generic;
using System.Text;
using Microsoft.VisualBasic.FileIO; //追加
// 空行を読み飛ばすのは仕様
// http://msdn.microsoft.com/ja-jp/library/microsoft.visualbasic.fileio.textfieldparser.readfields.aspx
namespace csvTest
{
class Program
{
static void Main(string[] args)
{
dumpCsv("C:\\dev\\csv\\test1.csv");
dumpCsv("C:\\dev\\csv\\test2.csv");
dumpCsv("C:\\dev\\csv\\test3.csv");
dumpCsv("C:\\dev\\csv\\test4.csv");
Console.ReadLine();
}
static void dumpCsv(string file)
{
Console.WriteLine(file + "================================");
TextFieldParser parser = new TextFieldParser(file,
System.Text.Encoding.GetEncoding("Shift_JIS"));
parser.TextFieldType = FieldType.Delimited;
parser.SetDelimiters(","); // 区切り文字はコンマ
parser.CommentTokens = new string[1] {"#"};
int line = 0, col = 0;
while (!parser.EndOfData)
{
++line;
col = 0;
string[] row = parser.ReadFields(); // 1行読み込み
Console.WriteLine("{0}", line);
// 配列rowの要素は読み込んだ行の各フィールドの値
foreach (string field in row)
{
++col;
Console.WriteLine("{0}:{1}", col, field);
}
Console.WriteLine("----------------------------");
}
parser.Close();
}
}
}
実行結果
C:\dev\csv\test1.csv================================
1
1:ジャック
2:12
3:戦士
4:説明1
----------------------------
2
1:バーン
2:17
3:騎士
4:説明2
----------------------------
3
1:マァム
2:15
3:僧侶
4:説明3
----------------------------
C:\dev\csv\test2.csv================================
1
1:ジャック
2:12
3:戦士
4:,や"が入力可能
----------------------------
2
1:バーン
2:17
3:騎士
4:説明2
改行を行う
----------------------------
3
1:マァム
2:15
3:僧侶
4:説明3
----------------------------
C:\dev\csv\test3.csv================================
1
1:ジャック
2:12
3:戦士
4:,や"が入力可能
----------------------------
2
1:バーン
2:17
3:騎士
4:説明2
ダブルクォート中に空の改行がある場合
----------------------------
3
1:マァム
2:15
3:僧侶
4:説明3
----------------------------
C:\dev\csv\test4.csv================================
1
1:ジャック
2:12
----------------------------
2
1:バーン
----------------------------
3
1:マァム
2:15
3:僧侶
4:説明3
----------------------------
この結果からTextFieldParserの動作として、次のことが言える。
・特別なライブラリのインストールが不要である。
・CommentTokensを設定することでコメント行を指定できる。
・空行は読み飛ばす。これはダブルクォーテーション中であっても例外でない。
この挙動は仕様である。
http://msdn.microsoft.com/ja-jp/library/microsoft.visualbasic.fileio.textfieldparser.readfields.aspx
・CSVを作成する機能は、存在しない。
CsvHelperを使用する例
TextParserの空行を読み飛ばす仕様が問題であったり、CSVを作成する必要がある場合はCsvHelperを使用するといい。
https://github.com/JoshClose/CsvHelper
上記からダウンロードして自分でビルドするか、パッケージマネージャーで次のコマンドを実行する。
Install-Package CsvHelperここでの検証は.NET3.5で行ったが、ライブラリとしては.NET2.0~4.5までサポートしている。
CSV読み込みのサンプル
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using CsvHelper;
// .NET3.5で検証
namespace csvTest
{
class Program
{
static void Main(string[] args)
{
dumpCsv("C:\\dev\\csv\\test1.csv");
dumpCsv("C:\\dev\\csv\\test2.csv");
dumpCsv("C:\\dev\\csv\\test3.csv");
dumpCsv("C:\\dev\\csv\\test4.csv");
Console.Read();
}
static void dumpCsv(string file)
{
Console.WriteLine(file + "================================");
var parser = new CsvReader(new StreamReader(file,
System.Text.Encoding.GetEncoding(932)));
parser.Configuration.Encoding = System.Text.Encoding.GetEncoding(932);
parser.Configuration.AllowComments = true;
parser.Configuration.Comment = '#';
parser.Configuration.HasHeaderRecord = false;
while (parser.Read())
{
for (var i = 0; i < parser.CurrentRecord.Length; ++i)
{
Console.WriteLine("{0}:{1}", i, parser.CurrentRecord.ElementAt(i));
}
Console.WriteLine("----------------------------");
}
parser.Dispose();
}
}
}
実行結果
C:\dev\csv\test1.csv================================
0:ジャック
1:12
2:戦士
3:説明1
----------------------------
0:バーン
1:17
2:騎士
3:説明2
----------------------------
0:マァム
1:15
2:僧侶
3:説明3
----------------------------
C:\dev\csv\test2.csv================================
0:ジャック
1:12
2:戦士
3:,や"が入力可能
----------------------------
0:バーン
1:17
2:騎士
3:説明2
改行を行う
----------------------------
0:マァム
1:15
2:僧侶
3:説明3
----------------------------
C:\dev\csv\test3.csv================================
0:ジャック
1:12
2:戦士
3:,や"が入力可能
----------------------------
0:バーン
1:17
2:騎士
3:説明2
ダブルクォート中に空の改行がある場合
----------------------------
0:マァム
1:15
2:僧侶
3:説明3
----------------------------
C:\dev\csv\test4.csv================================
0:ジャック
1:12
----------------------------
0:バーン
----------------------------
0:マァム
1:15
2:僧侶
3:説明3
----------------------------
CSV書き込みのサンプル
var csv = new CsvWriter(new StreamWriter("C:\\dev\\csv\\out.csv", false, System.Text.Encoding.GetEncoding(932)));
csv.WriteField("私はカゴメ");
csv.WriteField(12);
csv.WriteField(true);
csv.WriteField("\",などの記号");
csv.NextRecord();
csv.WriteField("2行目");
csv.WriteField("改行を2つ\n\nまぜる");
csv.NextRecord();
csv.Dispose();出力されたファイル
私はカゴメ,12,True,""",などの記号"
2行目,"改行を2つ
まぜる"この結果からCsvHelperの動作として、次のことが言える。
・空行があってもスキップをしない。
・Configuration.AllowComments,Commentでコメントの有無を指定できる。
・Configuration.HasHeaderRecordで一行目をヘッダとしてあつかうかどうかを指定できる。
・CSVファイルの作成も容易に行える。
・ここではやっていないが、Mapping を使用してオブジェクトと関連づけることもできる。
ExcelVBAでの実装例
Excelを用いて、CSVを開く方法
ExcelはCSVを開くことができるので、その機能を使用して実装してみる。
Public Sub test()
Call DumpCsv("C:\\dev\\csv\\test1.csv")
Call DumpCsv("C:\\dev\\csv\\test2.csv")
Call DumpCsv("C:\\dev\\csv\\test3.csv")
Call DumpCsv("C:\\dev\\csv\\test4.csv")
End Sub
Private Sub DumpCsv(ByVal path As String)
Debug.Print path & "=============================="
Dim wkb As Workbook
Dim wks As Worksheet
Application.ScreenUpdating = False
Set wkb = Application.Workbooks.Open(path)
Application.Windows(wkb.Name).Visible = False
Set wks = wkb.Sheets(1)
Dim r As Long
Dim c As Long
Dim maxRow As Long
Dim maxCol As Long
maxRow = wks.Cells(1, 1).SpecialCells(xlLastCell).Row
maxCol = wks.Cells(1, 1).SpecialCells(xlLastCell).Column
For r = 1 To maxRow
For c = 1 To maxCol
Debug.Print c & ":" & wks.Cells(r, c).Value
Next c
Debug.Print "----------------------"
Next r
Call wkb.Close(False)
Application.ScreenUpdating = True
End Sub実行結果
C:\\dev\\csv\\test1.csv==============================
1:ジャック
2:12
3:戦士
4:説明1
----------------------
1:バーン
2:17
3:騎士
4:説明2
----------------------
1:マァム
2:15
3:僧侶
4:説明3
----------------------
C:\\dev\\csv\\test2.csv==============================
1:#名前
2:歳
3:クラス
4:説明に("
5:)を入れる
----------------------
1:ジャック
2:12
3:戦士
4:,や"が入力可能
5:
----------------------
1:バーン
2:17
3:騎士
4:説明2
改行を行う
5:
----------------------
1:マァム
2:15
3:僧侶
4:説明3
5:
----------------------
C:\\dev\\csv\\test3.csv==============================
1:#空行の扱い
2:
3:
4:
----------------------
1:
2:
3:
4:
----------------------
1:ジャック
2:12
3:戦士
4:,や"が入力可能
----------------------
1:バーン
2:17
3:騎士
4:説明2
ダブルクォート中に空の改行がある場合
----------------------
1:#途中のコメント
2:
3:
4:
----------------------
1:マァム
2:15
3:僧侶
4:説明3
----------------------
C:\\dev\\csv\\test4.csv==============================
1:#列の数が異なる場合
2:
3:
4:
----------------------
1:
2:
3:
4:
----------------------
1:ジャック
2:12
3:
4:
----------------------
1:バーン
2:
3:
4:
----------------------
1:マァム
2:15
3:僧侶
4:説明3
----------------------このことより、Excelを用いて、CSVを開く場合、次のことがいえる。
・コメントの制御は行えない。
・Excel上のシートでCSVを開くのでデータの操作は、通常のExcelVBAと同様でいい。
・Excel上のシートで展開しているため、メモリ上のデータをアクセスする場合に比べてパフォーマンスは落ちる。
ADOを利用する場合
参照設定で「Microsoft ActiveX Data Objects x.x Library」を参照すると、データベースを操作するようにCSVを扱うことができる。
Public Sub tstAdo()
Call DumpCsvByADO("test1.csv")
Call DumpCsvByADO("test2.csv")
Call DumpCsvByADO("test3.csv")
Call DumpCsvByADO("test4.csv")
End Sub
Private Sub DumpCsvByADO(ByVal path As String)
Dim cnn As ADODB.Connection
Set cnn = New ADODB.Connection
cnn.Open ("Driver={Microsoft Text Driver (*.txt; *.csv)};" & _
"DBQ=C:\dev\csv\;" & _
"FirstRowHasNames=0;")
Dim rs As ADODB.Recordset
'FirstRowHasNames=0でヘッダを不要にできるが、バグで動かない。
' http://support.microsoft.com/kb/288343/ja
'http://support.microsoft.com/kb/257819/JA
Dim i As Long
Set rs = cnn.Execute("SELECT * FROM " & path)
Debug.Print path & "=============================="
Do While Not rs.EOF
For i = 0 To rs.Fields.Count - 1
Debug.Print rs.Fields(i).Value
Next i
Debug.Print "-------------------------"
rs.MoveNext
Loop
rs.Close
cnn.Close
Set cnn = Nothing
Set rs = Nothing
End Sub実行結果
test1.csv==============================
バーン
17
騎士
説明2
-------------------------
マァム
15
僧侶
説明3
-------------------------
test2.csv==============================
ジャック
12
戦士
,や"が入力可能
Null
-------------------------
バーン
17
騎士
説明2
改行を行う
Null
-------------------------
マァム
15
僧侶
説明3
Null
-------------------------
test3.csv==============================
Null
Null
Null
Null
-------------------------
ジャック
12
戦士
,や"が入力可能
-------------------------
バーン
17
騎士
説明2
ダブルクォート中に空の改行がある場合
-------------------------
# 途中のコメント
Null
Null
Null
-------------------------
マァム
15
僧侶
説明3
-------------------------
test4.csv==============================
Null
Null
Null
Null
-------------------------
ジャック
12
Null
Null
-------------------------
バーン
Null
Null
Null
-------------------------
マァム
15
僧侶
説明3
-------------------------
この結果より、ADOを使用した場合は次のことがいえる。
・データベースのようにCSVファイルを扱える。
・存在しないフィールドはNullとなる。
・コメントは効かない。
・一行目は必ずヘッダとして扱かわれる。そして、これはバグにより回避できない。
http://support.microsoft.com/kb/288343/ja
http://support.microsoft.com/kb/257819/JA
Pythonの実装例
csvモジュール
Pythonの場合は、標準で入っているcsv モジュールで対応可能。
http://docs.python.jp/2/library/csv.html
CSV読み込み
# -*- coding: utf-8 -*-
import csv
def dumpCsv(path):
print ('%s==============' % path)
reader = csv.reader(open(path,'rb'))
for row in reader:
print (', '.join(row))
dumpCsv('C:\\dev\\csv\\test1.csv')
dumpCsv('C:\\dev\\csv\\test2.csv')
dumpCsv('C:\\dev\\csv\\test3.csv')
dumpCsv('C:\\dev\\csv\\test4.csv')実行結果
C:\dev\csv\test1.csv==============
ジャック, 12, 戦士, 説明1
バーン, 17, 騎士, 説明2
マァム, 15, 僧侶, 説明3
C:\dev\csv\test2.csv==============
# 名前, 歳, クラス, 説明に(", )を入れる
ジャック, 12, 戦士, ,や"が入力可能
バーン, 17, 騎士, 説明2
改行を行う
マァム, 15, 僧侶, 説明3
C:\dev\csv\test3.csv==============
# 空行の扱い
ジャック, 12, 戦士, ,や"が入力可能
バーン, 17, 騎士, 説明2
ダブルクォート中に空の改行がある場合
# 途中のコメント
マァム, 15, 僧侶, 説明3
C:\dev\csv\test4.csv==============
# 列の数が異なる場合
ジャック, 12
バーン
マァム, 15, 僧侶, 説明3csvの書き込み
writer = csv.writer(open('C:\\dev\\csv\\out.csv', 'wb'),quoting=csv.QUOTE_ALL)
writer.writerow(['test', 'ああああ\nああああ', '記号",'])
writer.writerow(['test'])出力結果
"test","ああああ
ああああ","記号"","
"test"以上の結果より、csvモジュールを使用した場合は次のことがいえる。
・コメントは取り扱えない。
・ダブルクォーテーションで囲んだ場合のコンマ、改行、ダブルクォーテーションも扱える。
・CSVの作成も容易にできる。
Node.jsの実装例
node-csv を利用する例。
Node.jsの場合は、node-csvを用いることで、CSVの読み書きができる。
もし、cp932などの文字コードも使用する場合は、iconvモジュールも使用する。
インストール方法
node-csvのインストール
npm install csviconvのインストール
npm install iconvCSVの読み込み例
var csv = require('csv');
var fs = require('fs');
var Iconv = require('iconv').Iconv;
var conv = new Iconv('cp932','utf-8');
dumpCsv('test1.csv');
dumpCsv('test2.csv');
dumpCsv('test3.csv');
dumpCsv('test4.csv');
function dumpCsv(path) {
fs.readFile(path, function(err, sjisBuf) {
var buf = conv.convert(sjisBuf);
console.log(path + '================');
csv.parse(buf.toString(),{comment:'#'}, function(err, data) {
console.log(err);
console.log(data);
});
});
}実行結果
test1.csv================
null
[ [ 'ジャック', '12', '戦士', '説明1' ],
[ 'バーン', '17', '騎士', '説明2' ],
[ 'マァム', '15', '僧侶', '説明3' ] ]
test2.csv================
[Error: Invalid closing quote at line 1; found "ジ" instead of delimiter ","]
undefined
test3.csv================
null
[ [ 'ジャック', '12', '戦士', ',や"が入力可能' ],
[ 'バーン', '17', '騎士', '説明2\r\n\r\nダブルクォート中に空の改行がある場合' ],
[ 'マァム', '15', '僧侶', '説明3' ] ]
test4.csv================
null
[ [ 'ジャック', '12' ], [ 'バーン' ], [ 'マァム', '15', '僧侶', '説明3' ] ]test2.csvの読み込み結果がエラーになっている。
csv.parseは次のようにコメント中にダブルクォーテーションのあるデータを読み込めない。
# 名前,歳,クラス,説明に(",)を入れるこれを直すには、node_modules/csv/node_modules/csv-parse/lib/index.jsに次のようなパッチを適用する必要がある。
--- node_modules/csv/node_modules/csv-parse/lib/index_bk.js 2014-06-20 17:36:56.000000000 +0900
+++ node_modules/csv/node_modules/csv-parse/lib/index.js 2014-07-22 22:06:12.826116745 +0900
@@ -253,7 +253,7 @@
this.closingQuote = i;
i++;
continue;
- } else if (!this.field) {
+ } else if (!this.field && !this.commenting) {
this.quoting = true;
i++;
continue;
これを当てた場合の結果は次のようになる。
実行結果
test2.csv================
null
[ [ 'ジャック', '12', '戦士', ',や"が入力可能' ],
[ 'バーン', '17', '騎士', '説明2\r\n改行を行う' ],
[ 'マァム', '15', '僧侶', '説明3' ] ]CSVの書き込み例
var csv = require('csv')
var data = [
['xx', 'ああああ', 1],
['id', '"atagfa,asteata','#teat','aaa'],
['newline', 'tests\n\ntesat']
];
console.log(data);
csv.stringify(data, {quoted: true}, function(err, output) {
console.log(err);
console.log(output);
});作成される文字列
"xx","ああああ","1"
"id","""atagfa,asteata","#teat","aaa"
"newline","tests
tesat"
以上の結果より、node-csvを使用した場合は次のことがいえる。
・node-csvを使用するとCSVの読み書きが行える。
・コメントを取り扱うことも可能である。
・ただし、コメント周りに上記で説明した通りのバグか仕様があるので自分でパッチを作成して適用するか、コメントを使用しない。
CSVの設計について考察
ここではCSVファイルの書式をどう設計するか考察する。
CSVファイルを見ただけで、フィールドの意味がわかるようにヘッダファイルを指定した方が望ましい。
この際、コメントとして扱うようにするとよいだろう。
いくつかのライブラリを見たが、デフォルトでは"#"をコメントして扱う場合が多かった。
また、CSVを採用するメリットとして、Excelでデータが編集しやすいこともある。
Excelさえ使えれば、データを容易にデータを作成できるのは大きな魅力であり、そのメリットを崩すようなデータフォーマットにする場合は注意が必要である。
階層構造のデータ表現
ここでは、以下のように社員を含む部署データをCSVで表現する方法を考える。
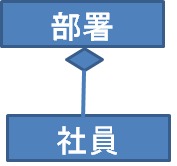
別のファイルとして扱う
親用のファイルと子用のファイルに分割する方法
もっとも単純なのは部署用データと社員用データを別のCSVとして扱うことである。
# 部署名,住所,電話番号
営業,東京,12345
開発,大阪,34566
管理,夢の国,44444# 社員名,所属部署,入社日,メール
大空翼,営業,1999/1/2,tubase@a.co.jp
岬太郎,営業,1999/1/3,misaki@a.co.jp
ジョセフジョースター,開発,2000/1/1,jojo@a.co.jp
空条丈太郎,開発,2000/1/3,jojo3@a.co.jp
しまこうさく,管理,2003/1/1,sima@a.co.jpこの欠点は、ファイルが完全に分かれリンクしていないので、データの親子関係がわかりづらいことにある。
子用のファイルを複数用意する案
別ファイルとして扱う方法の別の考え方として、社員のファイルを部署毎に分割して、部署.csvで紐づける方法がある。
# 部署名,住所,電話番号,社員ファイル
営業,東京,12345,営業社員.csv
開発,大阪,34566,開発社員.csv
管理,夢の国,44444,管理社員.csv大空翼,1999/1/2,tubase@a.co.jp
岬太郎,1999/1/3,misaki@a.co.jpジョセフジョースター,2000/1/1,jojo@a.co.jp
空条丈太郎,2000/1/3,jojo3@a.co.jpしまこうさく,2003/1/1,sima@a.co.jpこのメリットは、親の部署用のCSVから社員のCSVが紐づいていて親子関係がわかりやすいのと、部署名という親の名前を各レコードに記述しないですむので、ファイル数は増えるがトータルの容量が削減できることである。
1つのファイルとして扱う
もし、部署と社員を同一ファイルで扱わなければいけない場合を考える。
まず、本当にCSVファイル1つで表現しないとダメなのかを検討する。
XMLでよければ、それを採用する方法もあるし、複数にファイルを分割していい場合は、分割する。
しかし、XMLの編集はCSVより容易ではないし、ファイルをサーバーにアップロードするときなど、ファイルとして1つにまとめておきたいという要求があるのも事実である。
ここでは、階層的データをどのように、一つのファイルにまとめるかを考える。
なお、この場合、標準仕様でうたっている「フィールドの数は、ファイル全体を通じて同一であるべき」は満たせない。
1列目にデータの区分をつける
先頭のフィールドをデータ区分として「部署」なのか「社員」なのかを指定する。
部署,営業,東京,12345
部署,開発,大阪,34566
部署,管理,夢の国,44444
社員,大空翼,営業,1999/1/2,tubase@a.co.jp
社員,岬太郎,営業,1999/1/3,misaki@a.co.jp
社員,ジョセフジョースター,開発,2000/1/1,jojo@a.co.jp
社員,空条丈太郎,開発,2000/1/3,jojo3@a.co.jp
社員,しまこうさく,管理,2003/1/1,sima@a.co.jp実際にデータが多くなった場合に、部署と社員が入り乱れてわかりづらくなると考えられる。
1フィールドに子の情報をすべて含める
部署1行で社員をすべて格納する。
部署の情報の後のフィールドに社員の数だけフィールドを用意する。
1フィールドに社員の情報をすべてふくめる。
営業,東京,12345,"大空翼,1999/1/2,tubase@a.co.jp","岬太郎,1999/1/3,misaki@a.co.jp"
開発,大阪,34566,"ジョセフジョースター,2000/1/1,jojo@a.co.jp","空条丈太郎,2000/1/3,jojo3@a.co.jp"
管理,夢の国,44444,"しまこうさく,2003/1/1,sima@a.co.jp"この方法はExcelでデータを編集する際に、ユーザの入力が難しくなる。
たとえば部署の住所はセルのコピーアンドペーストで簡単に作成できるが、ユーザーのメールアドレスなどはセルのコピーアンドペーストができなくなる。
子のデータを特殊の文字で区切る
部署1行で社員をすべて格納する
その際、社員のデータが区別できるように開始文字と終端文字を既定する。
たとえば、フィールドに「\$大空翼」という文字があった場合、「\$」が現れるまでは、社員:大空翼のデータが格納されていると見なす。
営業,東京,12345,$大空翼,1999/1/2,tubase@a.co.jp,$,$岬太郎,営業,1999/1/3,misaki@a.co.jp,$
開発,大阪,34566,$ジョセフジョースター,2000/1/1,jojo@a.co.jp,$,$空条丈太郎,開発,2000/1/3,jojo3@a.co.jp,$
管理,夢の国,44444,$しまこうさく,2003/1/1,sima@a.co.jp,$Excelによる編集はセルのコピーが有効になるので、楽になる。
しかし、特殊な文字の決定などのルール決めが必要で、データ作成者との意識合わせが必要になる。
階層データのまとめ
いずれも一長一短であるので、CSVを破棄してXMLで行う等を含め、なにを優先するのか見極めて書式を決める必要がある。