e-Statでは政府が提供する様々な統計データをXMLやJSONで取得するAPIを使用できます。
APIの利用登録と動作テスト
1.下記のURLからAPIの利用申請をします。
http://www.e-stat.go.jp/api/regist-login/
2.APIを登録申請が完了すると「メールアドレス」と「パスワード」でログインが可能になります。
https://www.e-stat.go.jp/api/apiuser/php/index.php?action=login
3.ログイン後、再度ログイン画面に行くと「利用者情報変更/削除」と「アプリケーションIDの取得」がおこなえる画面が表示されます。
https://www.e-stat.go.jp/api/apiuser/php/index.php?action=login
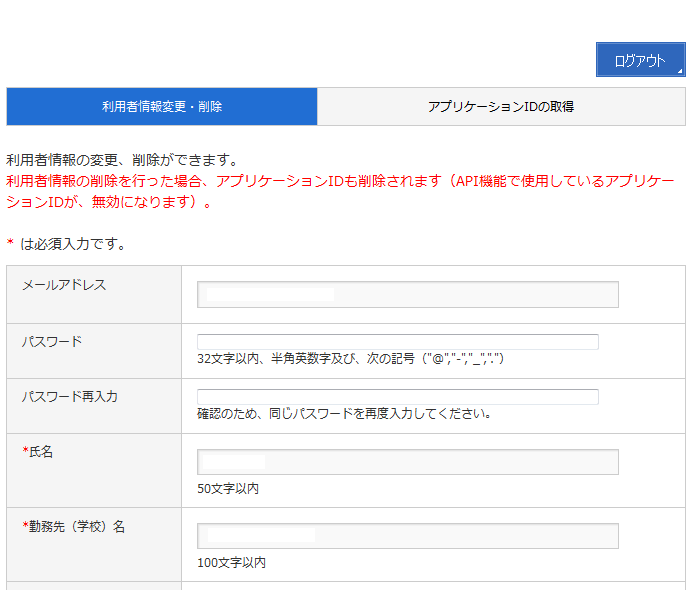
利用者情報変更では、登録時に指定したデータを変更することができます。
4.appIDの発行を行う。
「アプリケーションIDの取得」画面で名称とURLを入力して、「発行」ボタンを押すとappIDが取得できます。
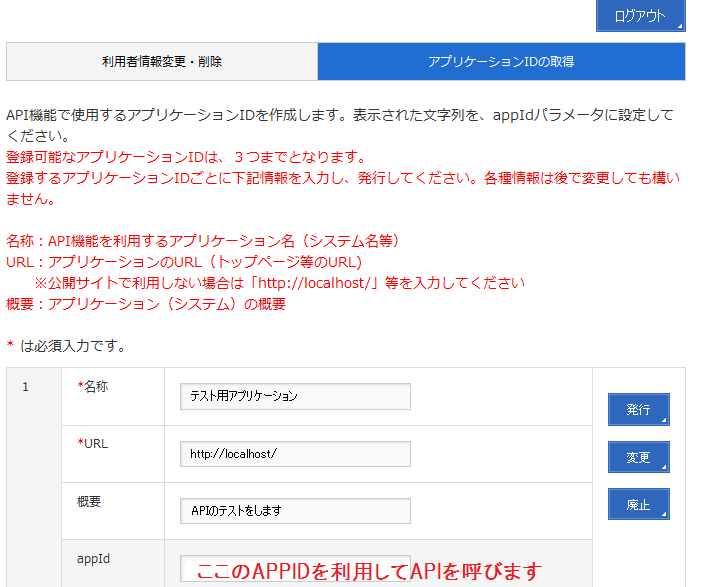
urlは存在しない場合は「http://localhost/」等を入力してください。
appIDは3個まで発行できます。
5.開発支援画面より各APIのテストを行います。
「機能概要」より「開発支援情報」を選択します。
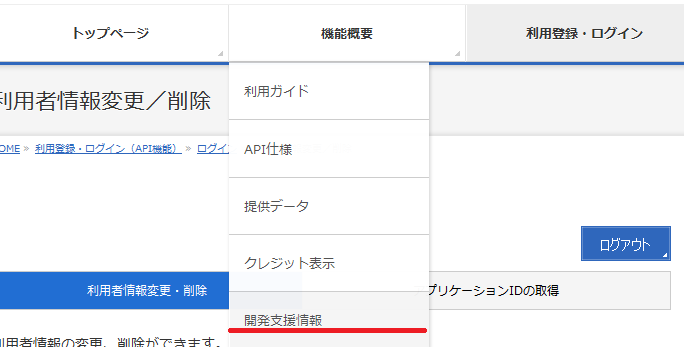
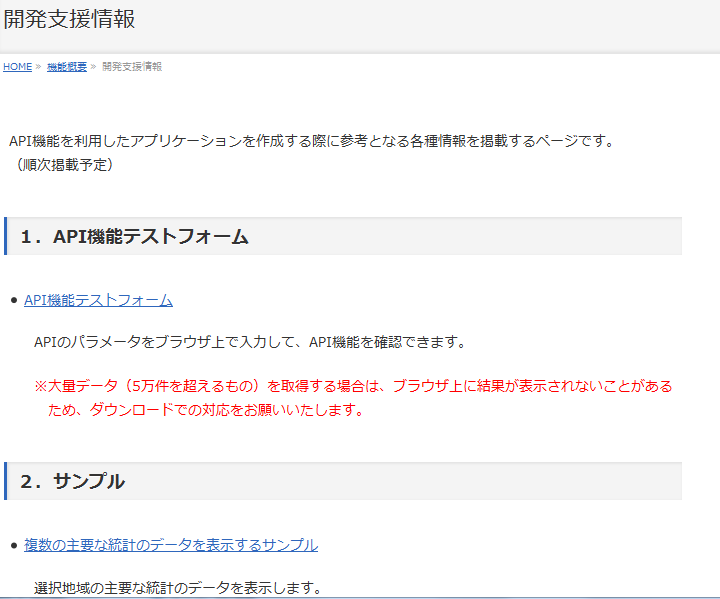
これにより、「API機能テストフォーム」や「サンプル」が利用できます。
APIの概要
API機能テストフォームで各APIの機能を確認できます。
また、APIの仕様は下記の画面から利用できます。
http://www.e-stat.go.jp/api/api-info/api-spec/
利用できるAPIの種類には下記の4つがあります。
・統計表情報取得
政府統計の総合窓口(e-Stat)で提供している統計表の情報を取得します。
リクエストパラメータの指定により条件を絞った情報の取得も可能です。
・メタ情報取得
指定した統計表IDに対応するメタ情報(表章事項、分類事項、地域事項等)を取得します。
・データ取得
指定した統計表ID又はデータセットIDに対応する統計データ(数値データ)を取得します。
リクエストパラメータの指定により条件を絞った情報の取得も可能です。
このデータはXMLとJSONで取得できます。
・データセット登録
統計データを取得する際の取得条件を登録します。
統計データの取得における絞り込み条件を「データセット」として指定することで、取得条件を省略することができます。
・データセット参照
登録されているデータセットの絞り込み条件等を参照します。
データセットIDが指定されていない場合は、利用者が使用できるデータセットの一覧が参照可能です。
基本的な使い方は次のようになります。
「統計表情報取得」で統計表を検索し、統計表のIDを取得し、「メタ情報取得」でメタ情報を取得後、「データ取得」で統計データを取得します。
サンプル
統計表情報の検索
このスクリプトでは統計表情報を取得します。
API_KEYと検索データ種別、検索キーワードを指定して実行します。
検索データ種別は下記の通りになります。
・1:統計情報(省略値)
・2:小地域・地域メッシュ
・3:社会・人口統計体系(都道府県・市区町村のすがた)
サンプルコード:
getStatsListSample.py
# !/usr/bin/python
# -*- coding: utf-8 -*-
import urllib
import urllib2
from lxml import etree
import sys
import codecs
# windows の場合...
sys.stdout = codecs.getwriter('cp932')(sys.stdout)
def main(argvs, argc):
if argc != 4:
print ("Usage #python %s api_key search_kind key_word" % argvs[0])
return 1
api_key = argvs[1]
search_kind = argvs[2]
# windows の場合...
key_word = argvs[3].decode('cp932')
key_word = urllib.quote(key_word.encode('utf-8'))
url = ('http://api.e-stat.go.jp/rest/1.0/app/getStatsList?appId=%s&lang=J&searchKind=%s&searchWord=%s' % (api_key, search_kind, key_word))
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
result = root.find('RESULT')
print ('RESULT==============')
print (result.find('STATUS').text)
print (result.find('ERROR_MSG').text)
print (result.find('DATE').text)
data_list = root.find('DATALIST_INF')
list_infs = data_list.xpath('.//LIST_INF')
for list_inf in list_infs:
print '--------------'
print (u'統計表ID:%s' % (list_inf.get('id')))
stat_name = list_inf.find('STAT_NAME')
if stat_name is not None:
print (u'政府統計名:%s %s' % (stat_name.get('code'), stat_name.text))
gov_org = list_inf.find('GOV_ORG')
if gov_org is not None:
print (u'作成機関名:%s %s' % (gov_org.get('code'), gov_org.text))
statistics_name = list_inf.find('STATISTICS_NAME')
if statistics_name is not None:
print (u'提供統計名及び提供分類名:%s' % (statistics_name.text))
title = list_inf.find('TITLE')
if title is not None:
print (u'表題:%s %s' % (title.get('no'), title.text))
cycle = list_inf.find('CYCLE')
if cycle is not None:
print (u'提供周期:%s' % (cycle.text))
survey_date = list_inf.find('SURVEY_DATE')
if survey_date is not None:
print (u'調査年月:%s' % (survey_date.text))
open_date = list_inf.find('OPEN_DATE')
if open_date is not None:
print (u'公開日:%s' % (open_date.text))
small_area = list_inf.find('SMALL_AREA')
if small_area is not None:
print (u'小地域属性:%s' % (small_area.text))
if __name__ == '__main__':
argvs = sys.argv
argc = len(argvs)
sys.exit(main(argvs, argc))
使用例:
python getStatsListSample.py API_KEY 1 雇用出力結果:
統計表ID:0003059047
政府統計名:00550100 経済産業省企業活動基本調査
作成機関名:00550 経済産業省
提供統計名及び提供分類名:経済産業省企業活動基本調査 統計表一覧-確報(データ)
平成22年企業活動基本調査確報-平成21年度実績-
表題:1-8 統計表(第1巻)〔事業組織に関する表〕 第8表 産業別、企業数、事業組織
別従業者数
提供周期:年次
調査年月:201001-201012
公開日:2012-03-31
小地域属性:0統計表IDの「0003059047」がデータ取得に使用できるIDになります。
メタ情報の表示
このスクリプトでは指定の統計IDのメタ情報を取得します。統計表情報の検索でした統計表IDをパラメータとしてメタ情報を取得します。
サンプルコード:
getMetaSample.py
# !/usr/bin/python
# -*- coding: utf-8 -*-
import urllib
import urllib2
from lxml import etree
import sys
import codecs
# windows の場合...
sys.stdout = codecs.getwriter('cp932')(sys.stdout)
def get_meta_data(api_key, stats_data_id):
"""
メタ情報取得
"""
url = ('http://api.e-stat.go.jp/rest/1.0/app/getMetaInfo?appId=%s&lang=J&statsDataId=%s' % (api_key, stats_data_id))
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
class_object_tags = root.xpath('//METADATA_INF/CLASS_INF/CLASS_OBJ')
class_object = {}
for class_object_tag in class_object_tags:
class_object_id = class_object_tag.get('id')
class_object_name = class_object_tag.get('name')
class_object_item = {
'id' : class_object_id,
'name' : class_object_name,
'objects' : {}
}
class_tags = class_object_tag.xpath('.//CLASS')
for class_tag in class_tags:
class_item = {
'code' : class_tag.get('code'),
'name' : class_tag.get('name'),
'level' : class_tag.get('level'),
'unit' : class_tag.get('unit')
}
class_object_item['objects'][class_item['code']] = class_item
class_object[class_object_id] = class_object_item
return class_object
def main(argvs, argc):
if argc != 3:
print ("Usage #python %s api_key stats_id" % argvs[0])
return 1
api_key = argvs[1]
stats_id = argvs[2]
ret = get_meta_data(api_key, stats_id)
for key in ret:
print ('======================')
print (key)
print ('name: %s' % ret[key]['name'])
for obj_code, obj in ret[key]['objects'].items():
print ('----------------------')
print ('code: %s' % obj_code)
print ('name: %s' % obj['name'])
print ('unit: %s' % obj['unit'])
print ('level: %s' % obj['level'])
if __name__ == '__main__':
argvs = sys.argv
argc = len(argvs)
sys.exit(main(argvs, argc))
使用例:
python getMetaSample.py API_KEY 0003059047出力例:
======================
cat01
name: 22_1-8 企業数、事業組織別従業者数
----------------------
code: 0011000
name: 常時従業者数(出向者を除く) 本社・本店 本社機能部門 その他
unit: None
level: 1
----------------------
code: 0029000
name: 常時従業者数(出向者を含む) 他企業等への出向者
unit: None
level: 1メタ情報には該当の統計表が利用しているカテゴリーとそのカテゴリーが取りうる値を表示します。
統計表をCSVにして出力
この例では統計表をCSVとして出力するサンプルを示します。統計表IDとCSVの出力パスを指定すると、CSVとして指定の統計表を出力します。
サンプルコード:
export_csv.py
# !/usr/bin/python
# -*- coding: utf-8 -*-
import sys
import urllib2
from lxml import etree
import csv
def export_statical_data(writer, api_key, stats_data_id, class_object, start_position):
"""
統計情報のエクスポート
"""
url = ('http://api.e-stat.go.jp/rest/1.0/app/getStatsData?limit=10000&appId=%s&lang=J&statsDataId=%s&metaGetFlg=N&cntGetFlg=N' % (api_key, stats_data_id))
if start_position > 0:
url = url + ('&startPosition=%d' % start_position)
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
row = []
datas = {}
value_tags = root.xpath('//STATISTICAL_DATA/DATA_INF/VALUE')
for value_tag in value_tags:
row = []
for key in class_object:
val = value_tag.get(key)
if val in class_object[key]['objects']:
level = '';
if 'level' in class_object[key]['objects'][val]:
if class_object[key]['objects'][val]['level'].isdigit():
level = ' ' * (int(class_object[key]['objects'][val]['level']) - 1)
text = ("%s%s" % (level , class_object[key]['objects'][val]['name']))
row.append(text.encode('utf-8'))
else:
row.append(val.encode('utf-8'))
row.append(value_tag.text)
writer.writerow(row)
next_tags = root.xpath('//STATISTICAL_DATA/TABLE_INF/NEXT_KEY')
if next_tags:
if next_tags[0].text:
export_statical_data(writer, api_key, stats_data_id, class_object, int(next_tags[0].text))
def get_meta_data(api_key, stats_data_id):
"""
メタ情報取得
"""
url = ('http://api.e-stat.go.jp/rest/1.0/app/getMetaInfo?appId=%s&lang=J&statsDataId=%s' % (api_key, stats_data_id))
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
class_object_tags = root.xpath('//METADATA_INF/CLASS_INF/CLASS_OBJ')
class_object = {}
for class_object_tag in class_object_tags:
class_object_id = class_object_tag.get('id')
class_object_name = class_object_tag.get('name')
class_object_item = {
'id' : class_object_id,
'name' : class_object_name,
'objects' : {}
}
class_tags = class_object_tag.xpath('.//CLASS')
for class_tag in class_tags:
class_item = {
'code' : class_tag.get('code'),
'name' : class_tag.get('name'),
'level' : class_tag.get('level'),
'unit' : class_tag.get('unit')
}
class_object_item['objects'][class_item['code']] = class_item
class_object[class_object_id] = class_object_item
return class_object
def export_csv(api_key, stats_data_id, output_path):
"""
指定の統計情報をCSVにエクスポートする.
"""
writer = csv.writer(open(output_path, 'wb'),quoting=csv.QUOTE_ALL)
class_object = get_meta_data(api_key, stats_data_id)
row = []
for key in class_object:
title = class_object[key]['name']
row.append(title.encode('utf-8'))
row.append('VALUE')
writer.writerow(row)
export_statical_data(writer, api_key, stats_data_id, class_object, 1)
def main(argvs, argc):
if argc != 4:
print ("Usage #python %s api_key stats_data_id output_path" % argvs[0])
return 1
api_key = argvs[1]
stats_data_id = argvs[2]
output_path = argvs[3]
export_csv(api_key, stats_data_id, output_path)
if __name__ == '__main__':
argvs = sys.argv
argc = len(argvs)
sys.exit(main(argvs, argc))
使用例:
python export_csv.py API_KEY 0003059047 output.csv出力例:
"22_1-8 企業数、事業組織別従業者数","22_1-8 産業","VALUE"
"企業数","平成17年度","27677"
"企業数","平成18年度","27917"
"企業数","平成19年度","29080"
"企業数","平成20年度","29355"
"企業数","平成21年度","29096"
"企業数","総合計","29096"
"企業数","合計","27871"
"企業数","鉱業、採石業、砂利採取業","36"
"企業数","製造業","13105"
"企業数","090 食料品製造業","1498"
"企業数","091 畜産食料品製造業","285"
"企業数","092 水産食料品製造業","222"
"企業数","093 精穀・製粉業","37"平成22年国勢調査の人口の地域メッシュ統計
地域メッシュ統計とは,緯度・経度に基づき地域を隙間なく網の目(Mesh)の区域に分けて,統計データをそれぞれの区域に編成したものです。
以下のような図になります。
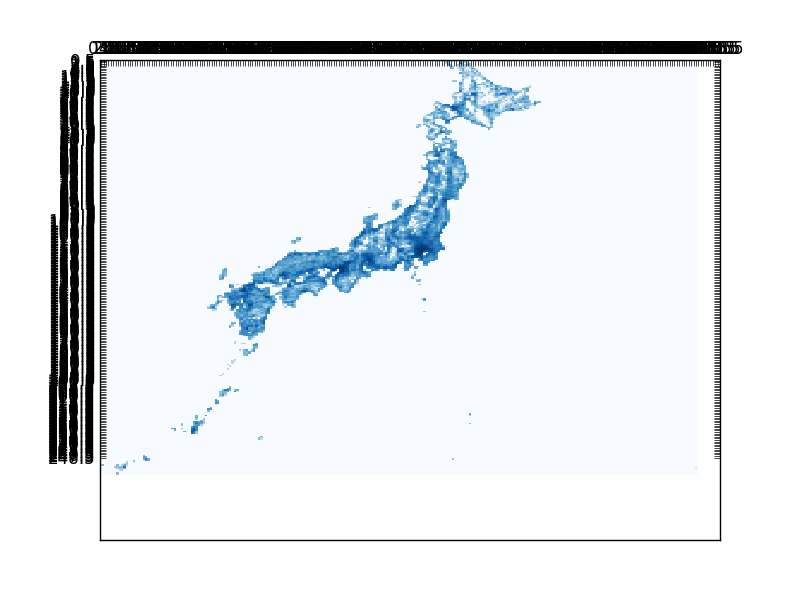
サンプルコード:
# !/usr/bin/python
# -*- coding: utf-8 -*-
import sys
import urllib
import urllib2
from lxml import etree
import csv
from collections import defaultdict
import json
from matplotlib import pyplot
import numpy as np
from math import *
def draw_heatmap(data):
# 描画する
fig, ax = pyplot.subplots()
heatmap = ax.pcolor(data, cmap=pyplot.cm.Blues)
ax.set_xticks(np.arange(data.shape[0]) + 0.5, minor=False)
ax.set_yticks(np.arange(data.shape[1]) + 0.5, minor=False)
ax.invert_yaxis()
ax.xaxis.tick_top()
pyplot.savefig('image.png')
pyplot.show()
return heatmap
def get_meta_data(api_key, stats_data_id):
"""
メタ情報取得
"""
url = ('http://api.e-stat.go.jp/rest/1.0/app/getMetaInfo?appId=%s&lang=J&statsDataId=%s' % (api_key, stats_data_id))
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
class_object_tags = root.xpath('//METADATA_INF/CLASS_INF/CLASS_OBJ')
class_object = {}
for class_object_tag in class_object_tags:
class_object_id = class_object_tag.get('id')
class_object_name = class_object_tag.get('name')
class_object_item = {
'id' : class_object_id,
'name' : class_object_name,
'objects' : {}
}
class_tags = class_object_tag.xpath('.//CLASS')
for class_tag in class_tags:
class_item = {
'code' : class_tag.get('code'),
'name' : class_tag.get('name'),
'level' : class_tag.get('level'),
'unit' : class_tag.get('unit')
}
class_object_item['objects'][class_item['code']] = class_item
class_object[class_object_id] = class_object_item
return class_object
def get_stats_list(api_key, search_kind, key_word):
key_word = urllib.quote(key_word.encode('utf-8'))
url = ('http://api.e-stat.go.jp/rest/1.0/app/getStatsList?appId=%s&lang=J&searchKind=%s&searchWord=%s' % (api_key, search_kind, key_word))
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
ret = []
data_list = root.find('DATALIST_INF')
list_infs = data_list.xpath('.//LIST_INF')
for list_inf in list_infs:
item = {
'id': list_inf.get('id')
}
stat_name = list_inf.find('STAT_NAME')
if stat_name is not None:
item['stat_name'] = stat_name.text
item['stat_name_code'] = stat_name.get('code')
gov_org = list_inf.find('GOV_ORG')
if gov_org is not None:
item['gov_org'] = gov_org.text
item['gov_org_code'] = gov_org.get('code')
statistics_name = list_inf.find('STATISTICS_NAME')
if statistics_name is not None:
item['statistics_name'] = statistics_name.text
title = list_inf.find('TITLE')
if title is not None:
item['title'] = title.text
cycle = list_inf.find('CYCLE')
if cycle is not None:
item['cycle'] = cycle.text
survey_date = list_inf.find('SURVEY_DATE')
if survey_date is not None:
item['survey_date'] = survey_date.text
open_date = list_inf.find('OPEN_DATE')
if open_date is not None:
item['open_date'] = open_date.text
small_area = list_inf.find('SMALL_AREA')
if small_area is not None:
item['small_area'] = small_area.text
ret.append(item)
return ret
def _get_stats_id_value(api_key, stats_data_id, class_object, start_position, filter_str):
"""
統計情報の取得
"""
url = ('http://api.e-stat.go.jp/rest/1.0/app/getStatsData?limit=10000&appId=%s&lang=J&statsDataId=%s&metaGetFlg=N&cntGetFlg=N%s' % (api_key, stats_data_id, filter_str))
if start_position > 0:
url = url + ('&startPosition=%d' % start_position)
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
ret = []
row = {}
datas = {}
value_tags = root.xpath('//STATISTICAL_DATA/DATA_INF/VALUE')
for value_tag in value_tags:
row = {}
for key in class_object:
val = value_tag.get(key)
if val in class_object[key]['objects']:
text = class_object[key]['objects'][val]['name']
row[key] = text.encode('utf-8')
else:
row[key] = val.encode('utf-8')
row['value'] = value_tag.text
ret.append(row)
return ret
def get_stats_id_value(api_key, stats_data_id, filter_str):
class_object = get_meta_data(api_key, stats_data_id)
return _get_stats_id_value(api_key, stats_data_id, class_object, 1, filter_str), class_object
def get_stats_id_list_value(api_key, stats_data_ids, filter):
filter_str = ''
for key in filter:
filter_str += ('&%s=%s' % (key, urllib.quote(filter[key].encode('utf-8'))))
ret = []
i = 0
for stats_data_id in stats_data_ids:
list, class_object = get_stats_id_value(api_key, stats_data_id, filter_str)
ret.extend(list)
i = i + 1
if i > 5:
break
return ret
def get_mesh_id(mesh_id, kind):
if kind == 1:
return mesh_id[0:4] + '0000'
elif kind == 2:
return mesh_id[0:6] + '00'
else:
raise Exception(mesh_id)
def collect_mesh_value(api_key, stats_data_ids, filter, kind):
filter_str = ''
for key in filter:
filter_str += ('&%s=%s' % (key, urllib.quote(filter[key].encode('utf-8'))))
ret = defaultdict(float)
i = 0
for stats_data_id in stats_data_ids:
list, class_object = get_stats_id_value(api_key, stats_data_id, filter_str)
sum = 0
for row in list:
key = get_mesh_id(row['area'], kind)
v = row['value']
if v.isdigit():
ret[key] += float(v)
i = i + 1
#if i > 5:
# break
return ret
def parse_mesh_to_num(mesh_id):
ret = {}
if len(mesh_id) == 4:
ret['p'] = float(mesh_id[0:2])
ret['u'] = float(mesh_id[2:4])
ret['q'] = 0.0
ret['v'] = 0.0
ret['r'] = 0.0
ret['w'] = 0.0
return ret
elif len(mesh_id) == 8:
ret['p'] = float(mesh_id[0:2])
ret['u'] = float(mesh_id[2:4])
ret['q'] = float(mesh_id[4])
ret['v'] = float(mesh_id[5])
ret['r'] = float(mesh_id[6])
ret['w'] = float(mesh_id[7])
return ret
else:
raise Exception(mesh_id)
def convert_mesh_to_num(mesh_id):
d1 = parse_mesh_to_num(mesh_id)
# 第2次地域は0~7なので80掛けている
x1 = (d1['u'] * 80) + (d1['v'] * 10) + d1['w'];
y1 = (d1['p'] * 80) + (d1['q'] * 10) + d1['r'];
return x1, y1
def main(argvs, argc):
wd = u'平成22年国勢調査-世界測地系(1KMメッシュ)20101001'
# API_KEY
api_key = 'API_KEY'
search_kind = '2'
stats_list = get_stats_list(api_key, search_kind, wd)
stats_ids = []
for stats in stats_list:
stats_ids.append(stats['id'])
# 人口総数でフィルタリング
values = collect_mesh_value(api_key, stats_ids, {'cdCat01':'T000608001'}, 2)
ret = []
max_x = 0
min_x = 9999
max_y = 0
min_y = 9999
for key in values.keys():
x, y = convert_mesh_to_num(key)
x = x
y = y
if min_x > x:
min_x = x
if max_x < x:
max_x = x
if min_y > y:
min_y = y
if max_y < y:
max_y = y
size_x = int(max_x - min_x) / 10 + 1
size_y = int(max_y - min_y) / 10 + 1
buff = [[0.0 for i in range(size_x)] for j in range(size_y)]
for key in values.keys():
x, y = convert_mesh_to_num(key)
x = int(x - min_x) / 10
y = (size_y-1) - int(y - min_y) / 10
# logを取らないと東京と他の地方の差が酷くて日本地図にならない。
buff[y][x] = log10(float(values[key]))
#print ('%s\t%s %d %d' % (key,values[key],x,y))
draw_heatmap(np.array(buff))
if __name__ == '__main__':
argvs = sys.argv
argc = len(argvs)
sys.exit(main(argvs, argc))
説明:
この図では人口を第2地域区画ごとに集計して、その常用対数をヒートマップとして表示しています。
常用対数を利用するのは、関東地区と他の地区の人口の差が多きすぎるため、まともな地図にならないからです。
第3地域区画(標準メッシュ)を全国で表示しようとするとメモリが莫大に消費されます。第一地域区画では、地図が荒すぎます。
この例では、すべて表示されるまで莫大な時間がかかります。
次の記事ではspatialiteに一旦データを保存することで処理の効率化を図っています。
政府統計窓口(eStat)の地域メッシュをWebブラウザで表示する方法
http://qiita.com/mima_ita/items/38784095a146c87dcd23
参考
地域メッシュ統計の特質・沿革:
http://www.stat.go.jp/data/mesh/pdf/gaiyo1.pdf
Python + matplotlib によるヒートマップ
http://qiita.com/ynakayama/items/7dc01f45caf6d87a981b