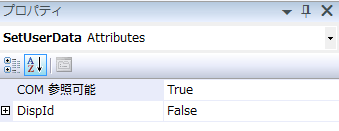
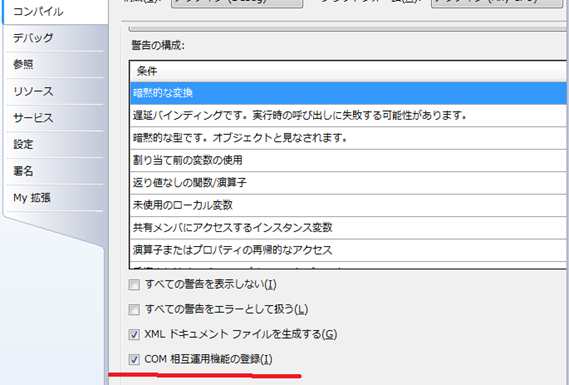
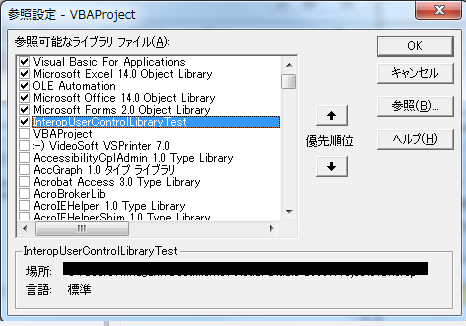
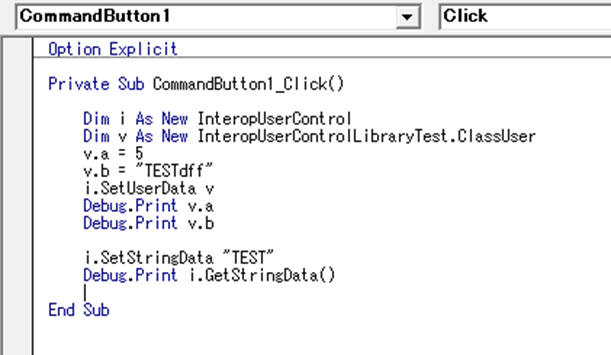
かって、JavaScriptのテンプレートとしてjquery.tmpl.jsが存在した。
jQuery公式サイトにものっていたが、現在はメンテナンスされておらず、公式から削除された。
https://github.com/BorisMoore/jquery-tmpl
しかしながら、同じ作者のJsRender、JsViewsといわれるライブラリが後継として存在している。
このドキュメントでは JsRender, JsViewsについての解説を行う。
http://www.jsviews.com/
JsRender
JsRenderはDOMやjQueryの依存関係なしで、軽量でありながら強力で拡張可能なテンプレートエンジンである。
JsRenderは以下からダウンロードすることが可能だ。
http://www.jsviews.com/#download
実装のサンプルとJsRenderの機能
JsRenderを利用した実装のサンプルを用いてJsRenderの機能を紹介する。
単純なオブジェクトの出力例
ここでは単純なオブジェクトをテンプレートを使用して出力するサンプルをしめす。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js" type="text/javascript"></script>
<script src="./jsrender.min.js" type="text/javascript"></script>
<script id="theTmpl" type="text/x-jsrender">
<p> Name: {{:name}} </p>
</script>
<script type="text/javascript">
$(function () {
var data = {
name: 'Jack'
};
var html = $('#theTmpl').render(data);
$('#result').append(html);
});
</script>
</head>
<body>
<div id="result"></div>
</body>
</html>
出力:
Name: Jack
まず、text/x-jsrenderというtypeのscript中にテンプレートの記述を行う。
<script id="theTmpl" type="text/x-jsrender">
<p> Name: {{:name}} </p>
</script>
これはrender functionによりデータとひもづけられてHTMLが作成される。
var html = $('#theTmpl').render(data);
この時、作成されるHTMLは次のようになる。
<p> Name: Jack </p>
配列の出力例
先の例ではテンプレートに渡すデータがオブジェクトだった。もし、配列を渡した場合はどうなるであろうか?
先のサンプルを配列に置き換えてみる。
var data = [
{name: 'Jack'},
{name: 'Sara'},
{name: 'Dick'}
];
ここで作成されるHTMLは次のようになる。
<p> Name: Jack </p>
<p> Name: Sara </p>
<p> Name: Dick </p>
データとして配列を渡した場合は、複数のデータが作成されることになる。
もし、渡すデータとしてはオブジェクトであり、そのプロパティが配列だった場合は、テンプレートの中でループをすることで表示することが可能だ。
以下のようなデータがあったとしよう。
var data = {
title: 'タイトル',
names:[
{name:'Jack'},
{name:'Sara'},
{name:'Dick'}
]
};
この時はテンプレートにループを加えるとよい。
<script id="theTmpl" type="text/x-jsrender">
<h1>Title {{:title}}</h1>
{{for names}}
<p>Name: {{:name}}</p>
{{/for}}
</script>
この時、生成されるHTMLは次の通りになる。
<h1>Title タイトル</h1>
<p>Name: Jack</p>
<p>Name: Sara</p>
<p>Name: Dick</p>
もし、データの配列中にさらに配列があったらどうであろうか?
var data = {
title: 'タイトル',
names:[
{name: 'test1', sub:['a','b','c']},
{name: 'test2', sub:['e','f','g']}
]
};
以下のように、テンプレート中のループの中にさらにループを記述するだけでよい。
<script id="theTmpl" type="text/x-jsrender">
<h1>Title {{:title}}</h1>
{{for names}}
<p>Name: {{:name}}</p>
{{for sub}}
<p>subitem: {{:}}</p>
{{/for}}
{{/for}}
</script>
この場合の出力結果は以下のようになる。
<h1>Title タイトル</h1>
<p>Name: test1</p>
<p>subitem: a</p>
<p>subitem: b</p>
<p>subitem: c</p>
<p>Name: test2</p>
<p>subitem: e</p>
<p>subitem: f</p>
<p>subitem: g</p>
オブジェクトのプロパティの列挙
オブジェクトのプロパティ名とその値を列挙するサンプルを示す。
以下のようなオブジェクトが存在しており、addressのプロパティ名と値を列挙したいものとする。
var data = [
{
"name": "Pete",
"address": {
"street": "12 Pike Place",
"city": "Seattle",
"ZIP": "98101"
}
},
{
"name": "Heidi",
"address": {
"street": "5000 Broadway",
"city": "Sidney",
"country": "Australia"
}
}
];
この場合はテンプレートにforではなくpropsを用いる。
すると、>keyでプロパティ名、>propでプロパティの値が取得できる。
<script id="theTmpl" type="text/x-jsrender">
<h1>Name {{:name}}</h1>
{{props address}}
<b>{{>key}}:</b> {{>prop}}<br/>
{{/props}}
</script>
この時のHTMLの出力は次のようになる。
<h1>Name Pete</h1>
<b>street:</b> 12 Pike Place<br/>
<b>city:</b> Seattle<br/>
<b>ZIP:</b> 98101<br/>
<h1>Name Heidi</h1>
<b>street:</b> 5000 Broadway<br/>
<b>city:</b> Sidney<br/>
<b>country:</b> Australia<br/>
文字列をテンプレートとして使用する場合
今までは、テンプレートの記述はscriptタグで行ったが、これを直接文字列で記述することも可能である。
var data = {
name: 'Jack'
};
$.templates('testTmpl', '<label>Name:</label>{{:name}}');
var html = $.render.testTmpl(data);
$('#result').append(html);
templates関数にテンプレート名とテンプレートを指定することでテンプレートを登録できる。登録したテンプレートは、テンプレート名を指定することで利用することができる。
<p>Name:Jack</p>
テンプレートの遅延読み込み
文字をテンプレートとして、利用できることを利用してテンプレートの遅延読み込みができることを意味する。
たとえば次のような、テキストファイルが存在する。
test.txt
<label> Name:</label> {{:name}}
これを以下のような、コードでtext.txtをテンプレートとして遅延読み込みができる。
<script type="text/javascript">
$(function () {
var data = {
name: 'Jack'
};
$.get('./test.txt', function(value) {
console.log(value);
var testTmp = $.templates(value);
var html = testTmp.render(data);
$('#result').append(html);
});
});
</script>
テンプレート内で別のテンプレートを使用する場合
テンプレート内でincludeタグを利用する事で別のテンプレートを使用する事が可能である。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js" type="text/javascript"></script>
<script src="./jsrender.min.js" type="text/javascript"></script>
<script id="peopleTemplate" type="text/x-jsrender">
<div>
{{:name}} lives in {{include tmpl="#addressTemplate"/}}
</div>
</script>
<script id="addressTemplate" type="text/x-jsrender">
<b>{{>address.city}}</b>
</script>
<script type="text/javascript">
$(function () {
var data = [
{
"name": "Pete",
"address": {
"city": "Seattle"
}
},
{
"name": "Heidi",
"address": {
"city": "Sidney"
}
}
];
var html = $('#peopleTemplate').render(data);
console.log(html);
$('#result').append(html);
});
</script>
</head>
<body>
<div id="result"></div>
</body>
</html>
この時のHTMLの出力は次のようになる
<div>
Pete lives in
<b>Seattle</b>
</div>
<div>
Heidi lives in
<b>Sidney</b>
</div>
includeタグはtmpl属性で指定したテンプレートの内容に置き換わっていることが確認できる。
このincludeを利用する事で、テンプレートの共通化を行える。
分岐の例
テンプレート中で{{if}}}タグを利用することでテンプレートを分岐することができる。
これは必要に応じて{{else}}タグも利用できる。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js" type="text/javascript"></script>
<script src="./jsrender.min.js" type="text/javascript"></script>
<script id="theTmpl" type="text/x-jsrender">
{{if displayType == 0}}
<p>Name: {{:name}} </p>
{{else displayType == 1}}
<p>Name: {{:azana}} </p>
{{else}}
<p>Name: {{:nickName}} </p>
{{/if}}
</script>
<script type="text/javascript">
$(function () {
var data = [
{
"name": "Kannu",
"azana": "Unchou",
"nickName": "Hige",
"displayType": 0
},{
"name": "Chouhi",
"azana": "Ekitoku",
"nickName": "Haruhi",
"displayType": 1
},
{
"name": "Ryubiu",
"azana": "Gentoku",
"nickName": "Kotei",
"displayType": 2
},
{
"name": "ShokatuRyou",
"azana": "Koumei",
"nickName": "awawa",
"displayType": 3
}
];
var html = $('#theTmpl').render(data);
console.log(html);
$('#result').append(html);
});
</script>
</head>
<body>
<div id="result"></div>
</body>
</html>
ここで作成されるHTMLの結果は以下のようになる。data.displayTypeにより表示される名前が切り替わっていることが確認できる。
<p>Name: Kannu </p>
<p>Name: Ekitoku </p>
<p>Name: Kotei </p>
<p>Name: awawa </p>
テンプレートに渡すデータのエスケープ処理
テンプレートに渡すデータ中の文字にHTMLのタグが存在する場合がある。このデータ中のタグをエスケープ処理を行うには、{{>データ名}}を用いる。
以下のサンプルで、エスケープ処理を行わない場合と、行った場合でどのような違いが生じるか確認する。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js" type="text/javascript"></script>
<script src="./jsrender.min.js" type="text/javascript"></script>
<script id="theTmpl" type="text/x-jsrender">
<p>{{:description}}</p>
<p>{{>description}}</p>
</script>
<script type="text/javascript">
$(function () {
var data = {description: "A <b>very nice</b> appartment"};
var html = $('#theTmpl').render(data);
console.log(html);
$('#result').append(html);
});
</script>
</head>
<body>
<div id="result"></div>
</body>
</html>
出力結果は以下の通りとなり、{{:}}の場合は、渡された文字データがそのまま出力されているが、{{>}}でエスケープ処理が適切になされることが確認できる。
<p>A <b>very nice</b> appartment</p>
<p>A <b>very nice</b> appartment</p>
まとめ
JsRenderを用いることで、JavaScriptのテンプレートを記述することができ、ビューとロジックの分離を容易に行うことができる。
JsViews
JsViewsはJsRenderとJsObservableと呼ばれるライブラリを用いてテンプレートとデータのリンクを行うことができる。
これにより、データに変更があった場合に描画の自動更新をすることが可能になる。
実装のサンプルとJsViewsの機能
JsViewsを利用した実装のサンプルを用いてJsViewsの機能を紹介する
JsViewsは、JsRenderと同じページからダウンロードできる。
data-linked tagの例
ここではdata-linked タグの使用例を見てみよう。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js" type="text/javascript"></script>
<script src="./jsviews.min.js" type="text/javascript"></script>
<script id="teamTemplate" type="text/x-jsrender">
<div class="buttons">
<button id="add">Add</button>
<button id="update">Update</button>
</div>
<ol>
{^{for members}}
<li>
{^{:name}}
{^{:age}}
<img class="remove" src="http://www.jsviews.com/resources/images/close.png" />
</li>
{{/for}}
</ol>
</script>
<script type="text/javascript">
$(function () {
var team = {
members: [
{name: "Robert", age:10},
{name: "Sarah", age:12}
]
};
var cnt = 1;
$.templates("#teamTemplate").link("#team", team)
.on("click", ".remove", function() {
var view = $.view(this);
$.observable(team.members).remove(view.index);
})
.on("click", "#add", function() {
$.observable(team.members).insert(0, {name: "new" + cnt++, age:1});
})
.on("click", "#update", function() {
for(var i = 0; i < team.members.length;++i) {
$.observable(team.members[i]).setProperty("age", team.members[i].age + 1);
}
});
});
</script>
</head>
<body>
<div id="team"></div>
</body>
</html>
出力例:
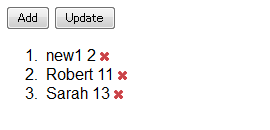
このプログラムを実際動作させると、Addボタンでアイテムの追加、xボタンでアイテムの削除、Updateボタンで年齢の更新が行われることがわかるだろう。つまり、ある種の操作により、表示の内容が更新されていることが確認できる。
どのように作っているかを説明する。
まずは、テンプレートの部分を見てみる。
<script id="teamTemplate" type="text/x-jsrender">
<div class="buttons">
<button id="add">Add</button>
<button id="update">Update</button>
</div>
<ol>
{^{for members}}
<li>
{^{:name}}
{^{:age}}
<img class="remove" src="http://www.jsviews.com/resources/images/close.png" />
</li>
{{/for}}
</ol>
</script>
JsRenderの場合、{{for members}}や{{:name}}となっていたものが、{^{for members}}や{^{:name}}になっているのがわかるだろう。「^」を使用することでデータがリンクされていることを示している。
次にデータとテンプレートを関連付けているところを見てみよう。
$.templates("#teamTemplate").link("#team", team)
.on("click", ".remove", function() {
var view = $.view(this);
$.observable(team.members).remove(view.index);
})
.on("click", "#add", function() {
$.observable(team.members).insert(0, {name: "new" + cnt++, age:1});
})
.on("click", "#update", function() {
for(var i = 0; i < team.members.length;++i) {
$.observable(team.members[i]).setProperty("age", team.members[i].age + 1);
}
});
「#tempTemplate」で指定したテンプレートとオブジェクト「team」を関連付けて「#team」に出力している。
.onで続くものは、どのようなイベントで、このテンプレートの内容が更新されるかを記述している。
更新する場合、追加には「\$.observable.indert」,削除には「\$.observable.remove」,特定のプロパティの更新には「\$.observable.setProperty」を使用する。
その他observableの機能はJsObservableのAPIを参照するとよい。
http://www.jsviews.com/#jsoapi
data-link属性の例
ここでは data-link属性を用いた例を紹介する。
INPUTなどにdata-link属性をつけることで、INPUTで入力した内容で、data-linkで指定したデータのプロパティの変更を行うことができるようになる。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js" type="text/javascript"></script>
<script src="./jsviews.min.js" type="text/javascript"></script>
<script id="theTmpl" type="text/x-jsrender">
<input data-link="name trigger=true"/>-
<input data-link="lastName trigger=true"/>
<br>
{^{:name}}-{^{:lastName}}
</script>
<script type="text/javascript">
$(function () {
var data = {
"name": "Jack",
"lastName": "Hanma"
};
var template = $.templates("#theTmpl");
template.link("#result", data);
$("#check").click(function(){
alert(JSON.stringify(data));
});
});
</script>
</head>
<body>
<div id="result"></div>
<button id="check">check</button>
</body>
</html>
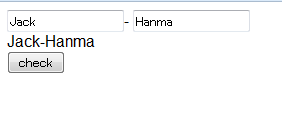
このサンプルを実行すると、INPUTの内容を変更すると、表示しているデータはもちろん、データとして渡したJSONの内容も変更されていることが確認できる。
まとめ
JsViewsを用いてテンプレートとデータを関連付けを行うと、画面の入力によりデータを容易に更新したり、Observerを使用してデータを更新することで画面の更新も容易に行える。
カスタムタグ
JsRenderとJsViewsの項目で{{for}}や{{else}}など様々なタグを紹介した。
JsViewsを使用することにより、開発者が任意のタグを作成することが可能だ。
この方法は下記に記述してある。
http://www.jsviews.com/#customtagsapi