目的
政府がオープンデータを叫び出して何年かが過ぎましたが、多くの政府が公開するデータはPDFベースになっています。
さすがにひと昔前のように紙をスキャンしただけのデータではなくなりましたがCSVやJSONなどの機械的に処理を行うのが楽であるとは言い難い現状です。
今回は下記のページに公開されているPDFを処理しやすい形式(CSV,JSON)に変換する実験を行います。
新型コロナウイルス感染症の感染拡大を踏まえたオンライン診療について
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/kenkou_iryou/iryou/rinsyo/index_00014.html
このページのPDFは以下の性質をもっています。
- 文字情報をもっている。(画像ではない)
- 日々更新される可能性がある
- 県によってはフォーマットが異なる可能性がある
実験環境
- Windows10 64bit
- Python 3.7.5 (tags/v3.7.5:5c02a39a0b, Oct 15 2019, 00:11:34) [MSC v.1916 64 bit (AMD64)]
- Java8
- Office365
PDFからテーブルを取得する方法
まずPDFからデータを取得する方法を考えてみます。
前述した実験環境においてPDFからテーブルの情報を取得するには3つの方法があります。
- PDFをWORDに変換してからテーブルを取得する
- tabulaを使用する
- camelotを使用する
PDFをWORDに変換してからテーブルを取得する
PDFをWORDで開いたのち、WORDのテーブルをExcelに張り付けることで処理しやすい形式に変換することが可能です。
この方法は、お手軽で少ない少ない件数のPDFを処理する場合において有効ですが、失敗するケースがあります。
たとえば、下記のPDFをダウンロードしてWORDで開いてみます。
https://www.mhlw.go.jp/content/000625002.pdf
下記のようなエラーが発生します。
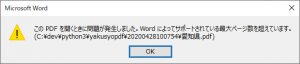
このPDFを開くときに問題が発生しました。Wordによってサポートされている最大ページ数を超えています。
このエラーメッセージはPDFの用紙サイズがWord文書の最大用紙サイズである558.7mm×558.7mmを超えている場合に発生します。
tabulaを使用する
tabula-javaはJavaで実装されており、PDFからテーブルの情報を抜き出すことが可能です。また、tabula-pyを使用することでPythonからtabula-javaを使用することが可能になります。
GUIでtabulaを使用する。
まずJava7以降の実行環境を構築してください。
次に下記のページから環境にあったファイルをダウンロードしてください。今回はWindowsで実行します。
https://tabula.technology/
解凍したexeを起動することでwebサーバーが起動して、ブラウザ経由でPDFの解析処理が可能になります。
ただし、exeを普通に起動するだけでは以下のようなエラーが発生します。
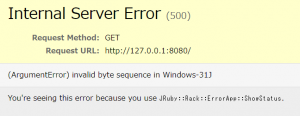
(ArgumentError) invalid byte sequence in Windows-31J
そのため以下のようなバッチファイルを記述して、バッチファイル経由で起動する必要があります。
set RUBYOPT=-EUTF-8
tabula.exeあとは、ブラウザを経由してPDFをアップロードし、PDF中のテーブルのエクスポートが可能になります。
参考:
http://deathon2legs.blogspot.com/2018/08/tabulapdf.html
Pythonでtabulaを使用する
tabula-pyを使用することでPythonでtabulaが使用できます。
tabula-pyを使用するにはPython3.5+,Java 8+の環境が必要になります。
インストール方法や必要要件は下記を参照してください。
https://tabula-py.readthedocs.io/en/latest/getting_started.html
実装例
下記のサンプルはPDFからテーブルを取得して施設名の一覧を出力するものになります。
import tabula
# 当該ページは日々更新されるため、下記のリンクから最新のURLを取得してください
# https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/kenkou_iryou/iryou/rinsyo/index_00014.html
df_list = tabula.read_pdf("https://www.mhlw.go.jp/content/000626082.pdf", pages='all', lattice=True)
for df in df_list:
for ix in df.index.values:
print(df.loc[ix][1])制限
PDFの複雑さによっては、表の内容の正確さを抽出することが難しい場合があります。すくなくとも新型コロナウイルス感染症の感染拡大を踏まえたオンライン診療についてで公開されているPDFのいくつは正確に抽出することはできませんでした。
camelotを使用する
camelotはPDFの表をより正確に抽出可能になっています。
camelotはghostscriptを使用しているのでWindowsの場合、以下からインストールを行う必要があります。
https://www.ghostscript.com/download/gsdnld.html
依存関係の詳細は以下を参照してください。
https://camelot-py.readthedocs.io/en/master/user/install-deps.html
インストール方法については下記を参照してください。今回はsource codeを使用してインストールしました。
https://camelot-py.readthedocs.io/en/master/user/install.html
なお、camelotはtabula-pyにくらべメモリを大量に使用する傾向があるので64bitのプロセスで実行することをお勧めします。すくなくとも東方の32bit環境では愛知県のデータは取得できませんでした。
実装例
下記のサンプルはPDFからテーブルを取得して施設名の一覧を出力するものになります。
import camelot
tables = camelot.read_pdf(
'https://www.mhlw.go.jp/content/000626082.pdf',
pages = 'all', # ページによってはメモリ使用量が跳ね上がるので1ページづつ解析した方がよい
line_scale = 30, # 数が大きいほど細い線でも認識するようになるが、大きすぎると文字を線とみなす デフォルト15
copy_text=['v'], # 空のデータを取得した場合に縦方向からデータをコピーする。表を結合している場合に有効
layout_kwargs = {
'char_margin': 0.25 # 2つの文字がこのマージンよりも接近している場合、それらは同じ行の一部と見なされます。 デフォルト:2
}
)
for tbl in tables:
for ix in tbl.df.index.values:
print(tbl.df.loc[ix][1])各方法の比較
PDFからテーブルを抽出する方法として以下の3つを比較します。
- PDFをWORDに変換してからテーブルを取得する
- tabulaを使用する
- camelotを使用する
PDFをWORDに変換してからテーブルを取得する方法は、お手軽に行えるメリットがありますが、今回使用するには問題があります。
まず、当該PDFは日々更新されています。そのため手動で行う処理が辛いです。仮にこの問題をマクロ等でカバーできたとしても、WORDの最大用紙サイズの制限があるため、完全に今回のデータを処理するには適さない方法です。
tabulaとcamelotについては精度の話を抜きにした場合、今回のPDFを機械的に読み取ることが可能です。
処理速度と使用メモリについてはtabulaが有利です。
逆に精度についてはcamelotが有利です。
camelotはいくつかのパラメータでチューニングが可能になっています。
主なパラメータの説明
https://camelot-py.readthedocs.io/en/master/api.html#main-interface
camelotはPDFMinerの機能を元に作成されており、PDFMinerで調整できる項目についてはlayout_kwargsのパラメータで指定できます。この項目についてはPDFMinerのドキュメントで確認できます。
https://euske.github.io/pdfminer/
(2020/05/03追記)
Camelotでは点線を含むPDFの処理が上手く動作しません。この対応については以下の通りになります。
https://needtec.sakura.ne.jp/wod07672/2020/05/03/camelot%e3%81%a7%e7%82%b9%e7%b7%9a%e3%82%92%e5%ae%9f%e7%b7%9a%e3%81%a8%e3%81%97%e3%81%a6%e5%87%a6%e7%90%86%e3%81%99%e3%82%8b/
「新型コロナウイルス感染症の感染拡大を踏まえたオンライン診療について」のページを解析する
ここまででPDFからテーブル情報を取得する基本的な方法について説明しました。
しかしながら、実際、抽出するにはいくつか問題点があります。
問題点
対応医療機関リストのPDFは日々更新され、そのURLも変わる
対応医療機関リストのPDFは日々更新されますが、そのURLは更新のたびに変更されるようです。
例えば東京都のURLは以下のようになります。
2020/04/28時点
https://www.mhlw.go.jp/content/000625693.pdf
2020/04/29時点
https://www.mhlw.go.jp/content/000626106.pdf
このため、PDFのURLは新型コロナウイルス感染症の感染拡大を踏まえたオンライン診療についてのリンクから取得する必要があります。
凡例の有無
データの1行目に凡例が入っている場合とない場合があります。
東京都の場合は凡例がありますが、北海道の場合はありません。
つまり県ごとに1ページ目のデータ行の取得位置を調整する必要があります。
各県ごとにページヘッダの取り扱いが異なる。
たとえば、北海道と茨城県のPDFを比較してみてください。
北海道は2ページ目以降にヘッダが含まれていますが、茨城県には含まれません。
つまり県ごとに2ページ目以降のデータ行の取得位置を調整する必要があります。
各県ごとに項目の取り扱いが異なる。
たとえば、北海道と愛知県を比較してみてください。
愛知県には所管保健所の列がありますが、北海道には存在しません。
つまり県ごとに必要な列の位置を調整する必要があります。
複数ページにまたがるデータ
以下は2020/04/28時点の奈良県のPDFです。
https://github.com/mima3/yakusyopdf/blob/master/20200428100754/%E5%A5%88%E8%89%AF%E7%9C%8C.pdf
ここで2ページと3ページ目にまたがっているデータが存在することが分かります。
施設名などは3ページ目にあります。
以下は同日の鳥取県のPDFです。
https://github.com/mima3/yakusyopdf/blob/master/20200428100754/%E9%B3%A5%E5%8F%96%E7%9C%8C.pdf
ここで6ページと7ページ目にまたがっているデータが存在することが分かります。
施設名などは6ページ目にあります。
つまり、施設名などが空の行を発見した場合に、改ページによって分割されている可能性を考慮する必要があります。
長い文字を含むデータ
たとえば以下のようにセルからはみ出るようなデータが存在する場合、結合された情報として抽出される可能性があります。

これを完全に回避する方法はなく、郵便番号の形式や電話番号の形式に当たらない場合は結合されているとみなして分割するなどの次善策を行う必要があります。
問題点を踏まえた上での処理
以下のようになります。
https://github.com/mima3/yakusyopdf
使用方法
# 新型コロナウイルス感染症の感染拡大を踏まえたオンライン診療についてのページからPDFをダウンロードしてフォルダに保存する
python download_pdf.py
# 作成したフォルダを指定して、PDFの内容からJSONとCSVを作成する
python analyze_pdf.py 20200428100754結果
https://github.com/mima3/yakusyopdf/tree/master/20200428100754
まとめ
ある程度まではPDFからCSVやJSONなどに変換することはできました。
しかしながら、完璧に行うことは不可能です。
たとえば、県ごとに細かい設定とかを行えるようにはしましたが、これはあくまで現時点のものであり、PDFの書き方が急に変ったりします。
このため官公庁のPDFを解析する場合は、解析した時点の日付を明示する必要があり、また、フォーマットが変わった場合の検知が肝要と思われます。