目的
MoodleというeLearningシステムがあります。
PHPとMySQLが動けば、わりと簡単に導入することが可能です。
今回はこのMoodleのプラグインを作成してみます。
syntaxhighlighterを参考に作成しています。
ソースコード
https://github.com/mima3/aa_image/tree/master/moodle_plugin/filter_aa_image
機能
エディタで入力した「aa_image]~[/aa_image]の内容を画像に変換するプラグインをsyntaxhighlighterを参考に作成します。
例
以下のような入力を行ったとする。
[aa_image]
____
/ \
/ _ノ ヽ、_ \
/ o゚((●)) ((●))゚o \ ほんとはVIPでやりたいんだお…
| (__人__) |
\ ` ⌒´ /
[/aa_image][aa_image]~[/aa_image]に記載された内容を圧縮してコードに変換する。
e9zQoPAYgiHo%2FZ79EBSvwIUm0Q9hwNS%2F37MHrARZWiH%2BcXMfWE%2Fz3vd7l8SDhGDqgIx%2Bhfz3%2B%2BZrvN%2FT8Wh6%2F%2Fs9nZoKSGygTD5YMUh74%2B7HTZMfN6543Lg%2BzDPgcePyx00tj5u6HjfOf9zYApZa8Lix61HDMojRNXB3QCzqiI9%2FsmtXfDzQXGSZGphD9iB55f3eBoVHPZMObVGAiwAdysUFAA%3D%3DこのURLをパラメータとしてIMGタグを作成する。
<img src="https://needtec.sakura.ne.jp/aa_image/image?d=e9zQoPAYgiHo%2FZ79EBSvwIUm0Q9hwNS%2F37MHrARZWiH%2BcXMfWE%2Fz3vd7l8SDhGDqgIx%2Bhfz3%2B%2BZrvN%2FT8Wh6%2F%2Fs9nZoKSGygTD5YMUh74%2B7HTZMfN6543Lg%2BzDPgcePyx00tj5u6HjfOf9zYApZa8Lix61HDMojRNXB3QCzqiI9%2FsmtXfDzQXGSZGphD9iB55f3eBoVHPZMObVGAiwAdysUFAA%3D%3D"/>コードの説明
| ファイル名 | 説明 |
|---|---|
| filter.php | 出力前にコンテンツを自動的に変換する処理を記述。詳細はFiltersを参照 |
| settings.php | 設定画面の実装。詳細はsettings.phpを参照 |
| thirdpartylibs.xml | 使用しているサードパーティのライブラリの情報を記載するXMLファイル。詳細はthirdpartylibs.xmlを参照 |
| version.php | バージョン情報。詳細はversion.phpを参照 |
| classes/privacy/provider.php | 個人データを扱うか扱わないという情報をMoodleに通知するためのインターフェイス。詳細はPrivacyAPIを参照 |
| lang/en/filter_aa_image.php | 多言語対応用のファイル。画面に表示する文字列を各言語毎に用意する |
settings.php
https://github.com/mima3/aa_image/blob/master/moodle_plugin/filter_aa_image/settings.php
設定画面は以下のような実装を行います。
if ($ADMIN->fulltree) {
$setting = new admin_setting_configtext(
'filter_aa_image/service_url',
new lang_string('serviceurl', 'filter_aa_image'),
new lang_string('serviceurl_desc', 'filter_aa_image'),
'http://needtec.sakura.ne.jp/aa_image/image');
$settings->add($setting);
}この実装を行った設定ページは以下のように表示されます。
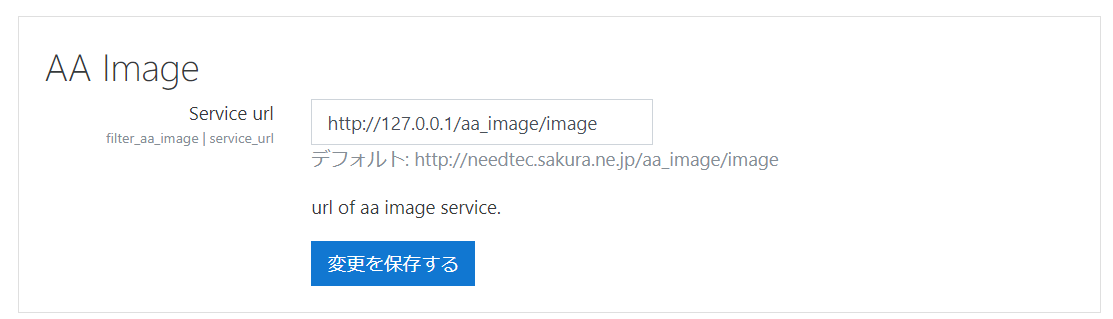
admin_setting_configtextは設定画面にテキスト入力できるコントロールを追加します。
第一引数の「filter_aa_image/service_url」は設定の名前を指定します。以下のような書式になります。
プラグイン名/一意の名称第二引数はテキストの横に表示されるラベルの表示文字になります。
ここでは直接文字を入力することなく、lang_stringを使用して多言語対応をしています。
第三引数は説明の表示文字になります。
ここでは直接文字を入力することなく、lang_stringを使用して多言語対応をしています。
第四引数はデフォルトの値になります。
その他詳細は下記のページを参照してください。
Creating a theme settings page
https://docs.moodle.org/dev/Creating_a_theme_settings_page
filter.php
出力前にコンテンツを自動的に変換する処理を記述します。
class filter_aa_image extends moodle_text_filter {
public function filter($text, array $options = array()) {
if (!is_string($text) || empty($text)) {
return $text;
}
$re = "~\[aa_image\](.*?)\[/aa_image\]~isu";
$result = preg_match_all($re, $text, $matches);
if ($result > 0) {
foreach ($matches[1] as $idx => $code) {
$code = str_replace(
['>','<','<pre>', '</pre>', '<p>', '</p>', '<br>', ' '],
['<', '>','', '', '', "", "\n", " "],
$code);
$key = base64_encode(gzdeflate($code, 9));
$newcode = '<p><img src="' . get_config('filter_aa_image', 'service_url') . '?d=' . urlencode($key). '"/></p>';
$text = str_replace($matches[0][$idx], $newcode, $text);
}
}
return $text;
}
moodle_text_filterを継承したクラスでfilterメソッドを実装することで実現できます。
やっている内容は[aa_image]で始まって[/aa_image]で終わる箇所を抜き出して置き換えをしています。
設定画面で設定した内容はget_configを使用して取得できます。
プラグインのインストール方法
下記のフォルダをZIP形式で圧縮します。
https://github.com/mima3/aa_image/tree/master/moodle_plugin/filter_aa_image
この圧縮したZIPをmoodleにアップロードします。
管理者でログインした後にサイドメニューの「サイト管理」を選択後、「プラグイン」タブを選びます。そこから「プラグインをインストールする」を選びます。
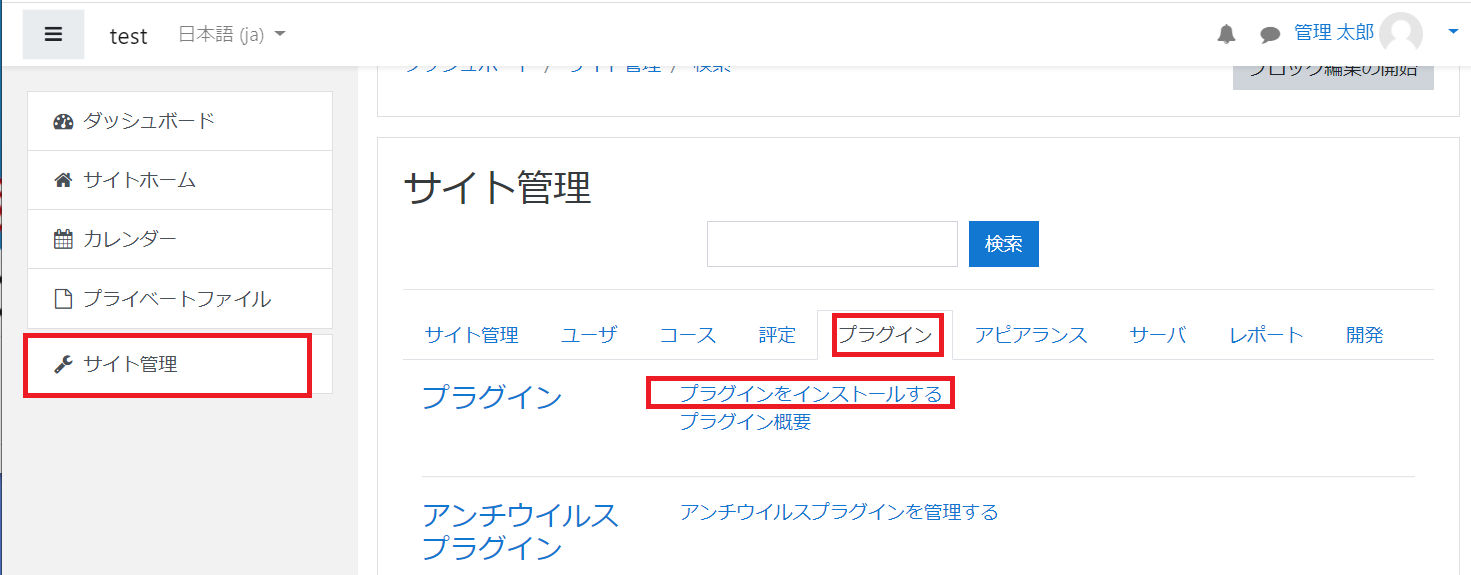
ZIPパッケージにZIPファイルをドラッグアンドドロップしたのちに、「ZIPファイルからプラグインをインストールする」を選択します。

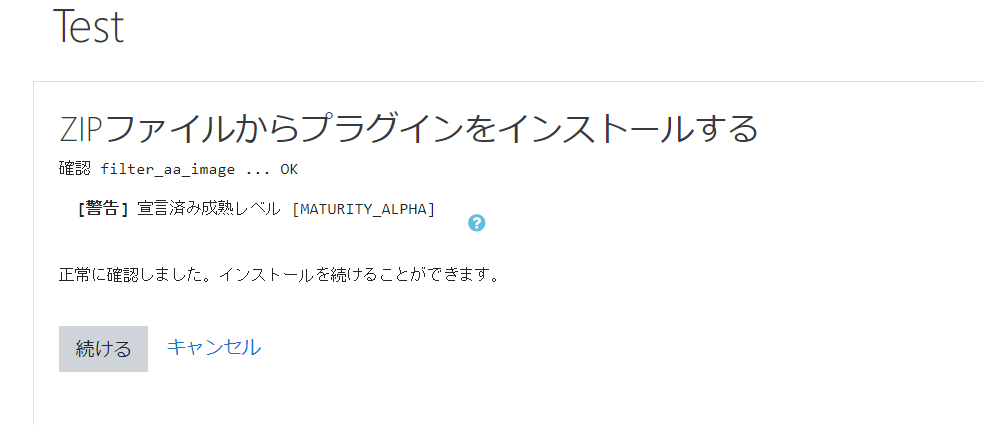
警告の内容を確認し、問題なければインストールを続けます。
moodleデータベースを更新します。
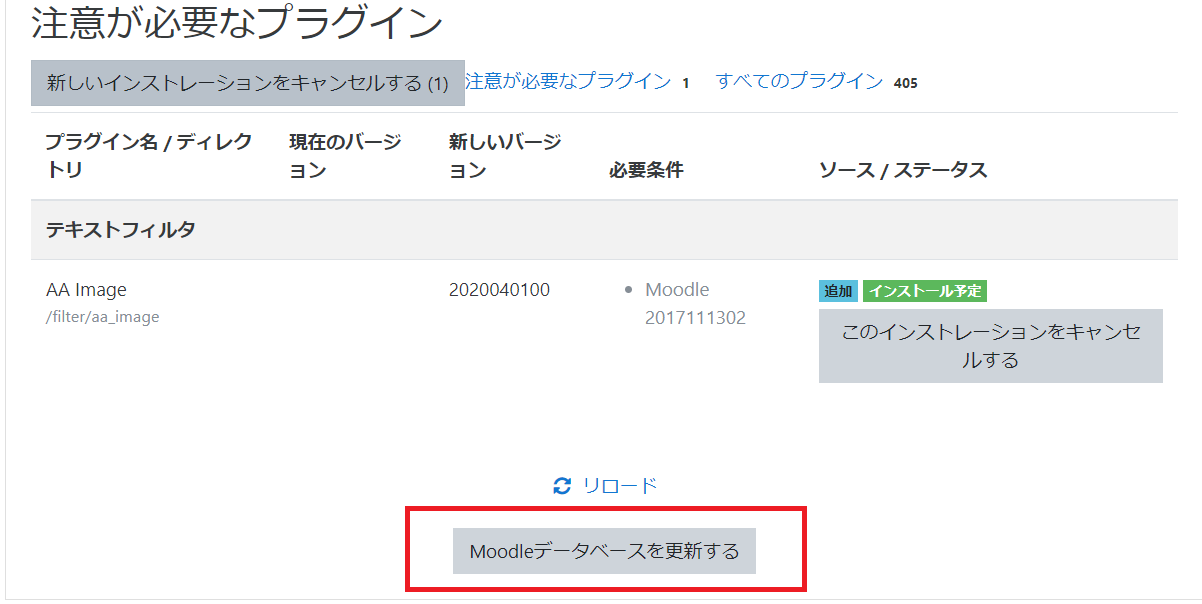
更新結果が表示されるので成功の場合は「続ける」を選択します。
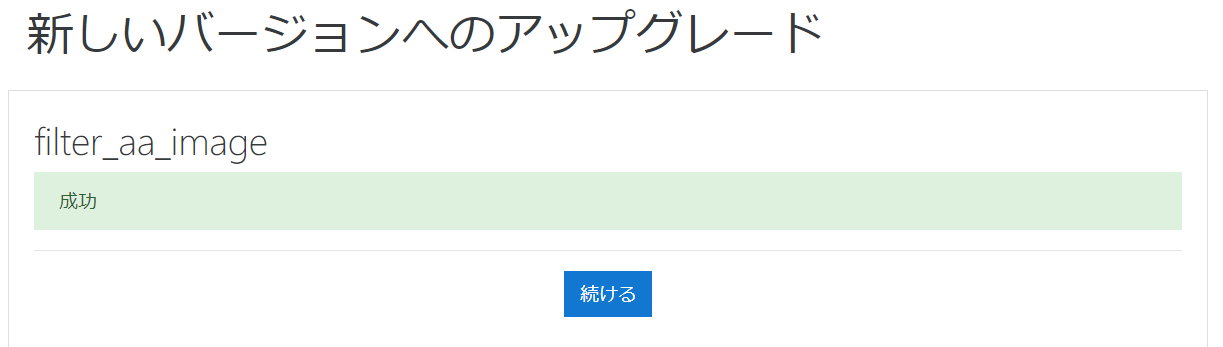
プラグインの管理画面が表示されるので必要に応じて設定を変更して「変更を保存する」を選択します。
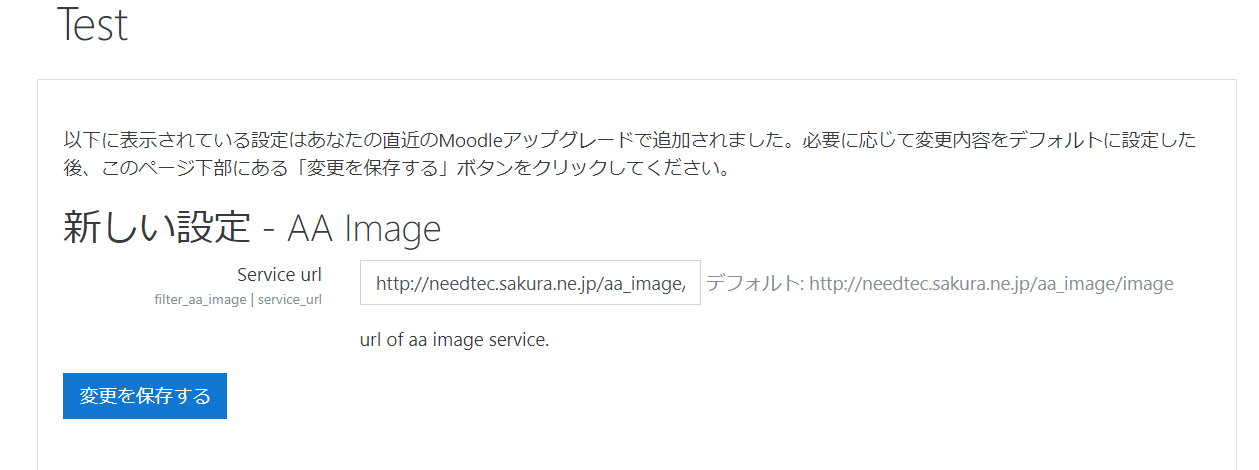
この時点でプラグインのインストールは完了しましたが、プラグインの機能は有効化されていないません。
プラグインの有効化の手順
管理者でログインした後にサイドメニューの「サイト管理」を選択後、「プラグイン」タブを選びます。そこから「プラグインの概要」を選びます。
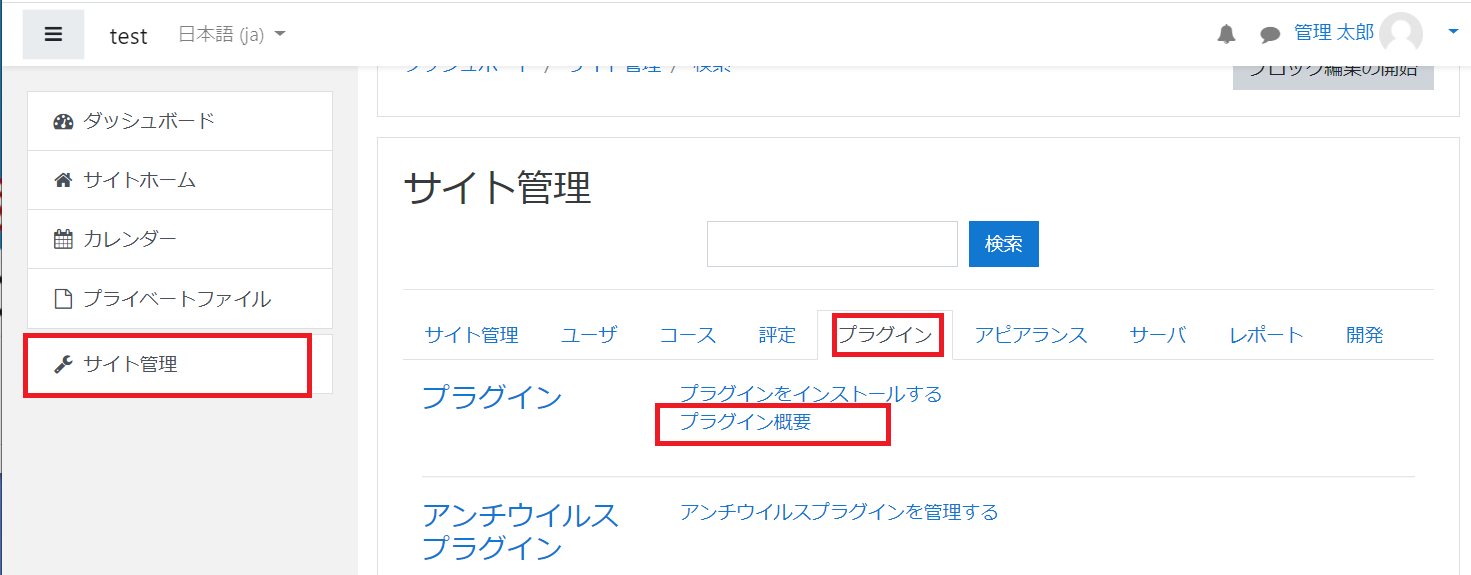
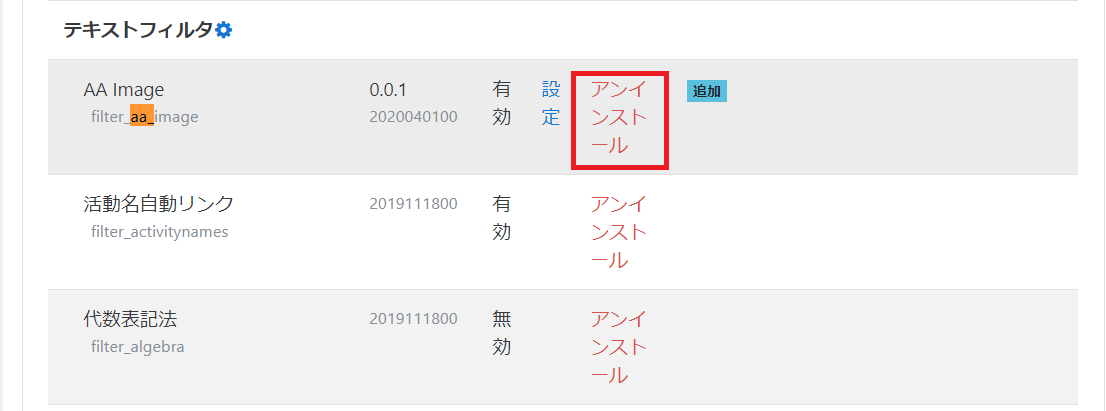
プラグイン名で検索して、そのカテゴリーの「設定」ボタンを押します。今回の場合はテキストフィルタの設定になります。
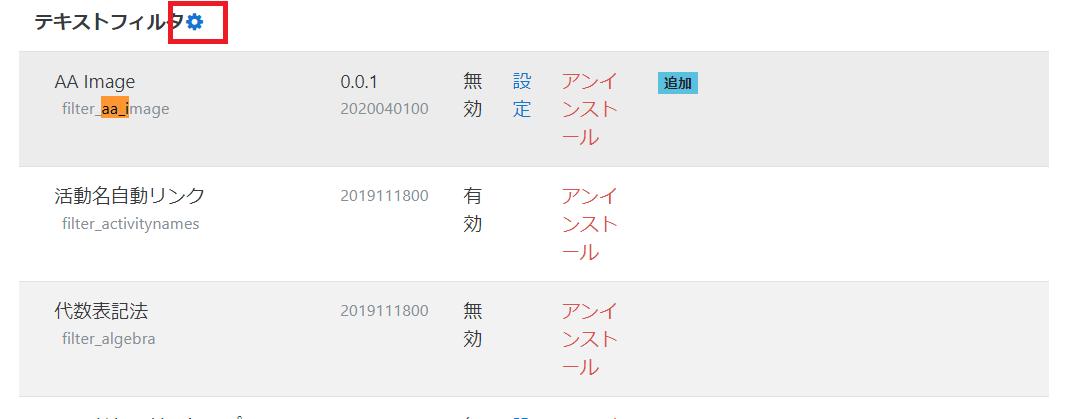
プラグイン名で検索して「有効?」の列をONにします。
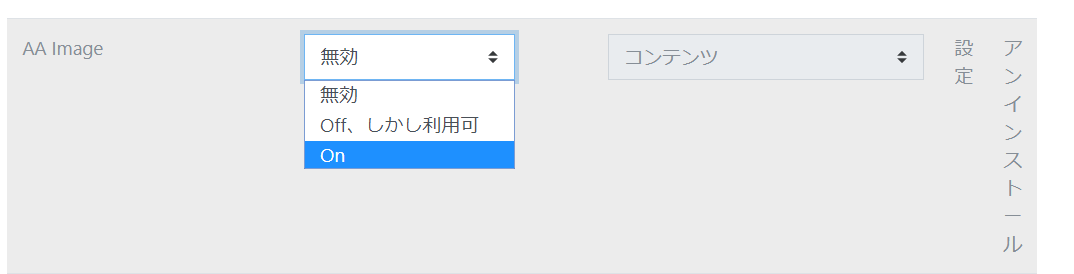
プラグインのアンインストール方法
管理者でログインした後にサイドメニューの「サイト管理」を選択後、「プラグイン」タブを選びます。そこから「プラグインの概要」を選びます。
プラグイン名で検索してアンインストールを実行します。