概要
peeweeはPython用のORMです。
以下のデータベースの操作が行えます。
・SQLite
・MySQL
・Postgres
・AWSP
・BerkeleyDatabase(未検証)
詳細は下記のドキュメントを参照してください。
https://peewee.readthedocs.org/en/latest/index.html
更新履歴
2019.08.03 サンプルコードを変更 Python2.7 → Python3.7 & Peewee 3.9.6
環境
Windows10
Python 3.7.4(32bit)
Peewee 3.9.6
インストール方法
pip install peewee
簡単な例
SQLiteによる簡単なサンプルを以下に示します。
from peewee import *
from datetime import date
db = SqliteDatabase(':memory:')
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db # This model uses the "people.db" database.
class Pet(Model):
owner = ForeignKeyField(Person, related_name='pets')
name = CharField()
animal_type = CharField()
class Meta:
database = db # this model uses the people database
try:
db.create_tables([Person, Pet])
with db.transaction():
# オブジェクトを作ってSaveすることでINSERTする
uncle_bob = Person(name='Bob', birthday=date(1960, 1, 15), is_relative=True)
uncle_bob.save() # bob is now stored in the database
# createでINSERTする
grandma = Person.create(name='Grandma', birthday=date(1935, 3, 1), is_relative=True)
herb = Person.create(name='Herb', birthday=date(1950, 5, 5), is_relative=False)
bob_kitty = Pet.create(owner=uncle_bob, name='Kitty', animal_type='cat')
herb_fido = Pet.create(owner=herb, name='Fido', animal_type='dog')
herb_mittens = Pet.create(owner=herb, name='Mittens', animal_type='cat')
herb_mittens_jr = Pet.create(owner=herb, name='Mittens Jr', animal_type='cat')
print ("全部取得-----------------")
for person in Person.select():
print(person.name, person.is_relative)
print("catのみ取得-----------------")
query = Pet.select().where(Pet.animal_type == 'cat')
for pet in query:
print(pet.name, pet.owner.name)
print("Joinの例-----------------")
query = (Pet
.select(Pet, Person)
.join(Person)
.where(Pet.animal_type == 'cat'))
for pet in query:
print(pet.name, pet.owner.name)
print("更新の例-----------------")
update_pet = Pet.get(Pet.name=='Kitty')
update_pet.name = 'Kitty(updated)'
update_pet.save()
query = (Pet
.select(Pet, Person)
.join(Person)
.where(Pet.animal_type == 'cat'))
for pet in query:
print(pet.name, pet.owner.name)
print("削除の例-----------------")
del_pet = Pet.get(Pet.name=='Mittens Jr')
del_pet.delete_instance()
query = (Pet
.select(Pet, Person)
.join(Person)
.where(Pet.animal_type == 'cat'))
for pet in query:
print(pet.name, pet.owner.name)
db.commit()
except IntegrityError as ex:
print (ex)
db.rollback()
この例のようにpeeweeを用いればSQL文を記述することなく、データベースの操作が行えます。
その他、グループ化や、max,min関数を使用したクエリーについては下記を参考にしてください。
https://peewee.readthedocs.org/en/latest/peewee/querying.html
SUBSTRなどの関数を使う場合
SUBSTRなどの関数を使う場合は、SQL()を使用します。
print ('SUBSTRの例')
for r in Pet.select(SQL('SUBSTR(name,1,1)').alias('a1')):
print (r.a1)
この例ではname列の1文字目をSUBSTR関数で取得して、それにa1という列名を与えています。
MAXを使って最大値を取得する場合
fn.MAXで関数を指定して,クエリーからscalar()を使用して値を取得する。
max = LiveChatMessage.select(
fn.MAX(LiveChatMessage.offset_time_msec)
).where(LiveChatMessage.video_id == video_id).scalar()
print(max)
大量データの作成
一度に大量のデータを作成する場合は、insert_manyを使用します。
from peewee import *
from datetime import date
db = SqliteDatabase(':memory:')
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
data_source = [
{'name' : 'test1' , 'birthday' : date(1960, 1, 15), 'is_relative' : True},
{'name' : 'test2' , 'birthday' : date(1960, 2, 15), 'is_relative' : True},
{'name' : 'test3' , 'birthday' : date(1960, 3, 15), 'is_relative' : True},
{'name' : 'test4' , 'birthday' : date(1960, 4, 15), 'is_relative' : True},
{'name' : 'test5' , 'birthday' : date(1960, 5, 15), 'is_relative' : True},
]
db.create_tables([Person])
try:
with db.transaction():
Person.insert_many(data_source).execute()
print ("全部取得-----------------")
for person in Person.select():
print (person.name, person.birthday, person.is_relative)
except IntegrityError as ex:
print (ex)
db.rollback()
DISTINCTの使用方法
DISTINCTは下記のように利用します。
q = Person.select(Person.name).distinct()
print (q.sql())
for person in q:
print (person.name, person.birthday, person.is_relative)
作成されるSQLは下記のようになります。
'('SELECT DISTINCT "t1"."name" FROM "person" AS "t1"', [])
条件を動的に組み立てる
下記の例では、operation_companyとrailway_lineを条件にクエリを取得しています。
def get_dynamic_sql(name = None, is_relative = None):
ret = []
query = Person.select()
cond = None
if not name is None:
cond = (Person.name == name)
if not is_relative is None:
if cond:
cond = cond & (Person.is_relative == is_relative)
else:
cond = (Person.is_relative == is_relative)
rows = query.where(cond)
for r in rows: # ここでSQLを発行する
ret.append(r.name)
return ret
この例ではパラメータの指定方法により4種類のSQLが作成されます。
| name |
is_relative |
作られるSQL |
| None |
None |
SELECT "t1"."id", "t1"."name", "t1"."birthday", "t1"."is_relative" FROM "person" AS "t1 |
| None以外 |
None |
SELECT "t1"."id", "t1"."name", "t1"."birthday", "t1"."is_relative" FROM "person" AS "t1" WHERE ("t1"."name" = ?) |
| None |
None以外 |
SELECT "t1"."id", "t1"."name", "t1"."birthday", "t1"."is_relative" FROM "person" AS "t1" WHERE ("t1"."is_relative" = ?) |
| None以外 |
None以外 |
SELECT "t1"."id", "t1"."name", "t1"."birthday", "t1"."is_relative" FROM "person" AS "t1" WHERE (("t1"."name" = ?) AND ("t1"."is_relative" = ?)) |
また、作成されたSQLが実際に発行されるタイミングは使用する時です。
この挙動を利用することにより、動的に複雑な条件のクエリを組み立てることができます。
JOINについて
使用できるJOIN
peewee 2.4.5ではRIGHTやFULL JOINはできません。
INNER JOINかLEFT OUTER JOINのみ使用できます。
query = Curve.select(Curve, RailRoadSection).join(RailRoadSection, JOIN_FULL)
JOIN_FULLを指定した場合、例外が発生します。
peewee.OperationalError: RIGHT and FULL OUTER JOINs are not currently supported
LEFT OUTER JOINの例
取得したレコードに結合中のテーブル名があります。dir関数でレコードの内容をするといいでしょう。
# モデル
from peewee import *
from datetime import date
db = SqliteDatabase(':memory:')
class Group(Model):
name = CharField()
class Meta:
database = db # This model uses the "people.db" database.
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
group = ForeignKeyField(Group, related_name='group')
class Meta:
database = db # This model uses the "people.db" database.
class Pet(Model):
owner = ForeignKeyField(Person, related_name='pets', null=True)
name = CharField()
animal_type = CharField()
class Meta:
database = db # this model uses the people database
try:
db.create_tables([Person, Pet, Group])
with db.transaction():
#
grp1 = Group(name='花組')
grp1.save()
grp2 = Group(name='奇面組')
grp2.save()
# オブジェクトを作ってSaveすることでINSERTする
uncle_bob = Person(name='Bob', birthday=date(1960, 1, 15), is_relative=True, group=grp1)
uncle_bob.save() # bob is now stored in the database
# createでINSERTする
grandma = Person.create(name='Grandma', birthday=date(1935, 3, 1), is_relative=True, group=grp2)
herb = Person.create(name='Herb', birthday=date(1950, 5, 5), is_relative=False, group=grp1)
bob_kitty = Pet.create(owner=herb, name='Kitty', animal_type='cat')
herb_fido = Pet.create(owner=herb, name='Fido', animal_type='dog')
herb_mittens = Pet.create(owner=herb, name='Mittens', animal_type='cat')
herb_mittens_jr = Pet.create(owner=herb, name='Mittens Jr', animal_type='cat')
ginga = Pet.create(owner=None, name='Mittens Jr', animal_type='cat')
print ("全部取得-----------------")
for group in Group.select():
print(group.name)
for person in Person.select():
print(person.name, person.is_relative, person.group)
for pet in Pet.select():
print(pet.owner, pet.name, pet.animal_type)
print("inner Joinの例-----------------")
query = (Pet
.select(Pet, Person)
.join(Person))
for pet in query:
print(pet.name, pet.owner.name)
print("left outer Joinの例-----------------")
query = (Pet
.select(Pet, Person)
.join(Person, JOIN.LEFT_OUTER))
for pet in query:
print(pet.name, pet.owner)
#print("right outer Joinの例-----------------")
#query = (Pet
# .select(Pet, Person)
# .join(Person, JOIN.FULL))
#for pet in query:
# print(pet.name, pet.owner)
except IntegrityError as ex:
print (ex)
db.rollback()
複数のテーブルをJOINする場合
複数のテーブルをJOINする場合は、switchを使用してどのテーブルに結合するかを明示しなければなりません。
http://stackoverflow.com/questions/22016778/python-peewee-joins-multiple-tables
# http://stackoverflow.com/questions/22016778/python-peewee-joins-multiple-tables
query = (TimeTableItem
.select(TimeTableItem, TimeTable, BusStop)
.join(TimeTable, on = (TimeTableItem.timeTable << list(timetableids.keys())))
.switch(TimeTableItem)
.join(BusStop, on=(TimeTableItem.busStop == BusStop.id))
)
for r in query:
print (r.busStop.stopName)
自己結合
自己結合を行う場合、aliasで別名のオブジェクトを作成しておき、それを利用する
fromBusStop = BusStopOrder.alias()
toBusStop = BusStopOrder.alias()
query = (fromBusStop
.select(fromBusStop, toBusStop, BusStop)
.join(
toBusStop,
on=((toBusStop.route == fromBusStop.route) & (toBusStop.stopOrder > fromBusStop.stopOrder))
.alias('toBusStopOrder')
)
.switch(toBusStop)
.join(BusStop, on=(toBusStop.busStop==BusStop.id))
.where((fromBusStop.busStop==from_bus_stop))
)
for r in query:
print (r.toBusStopOrder.busStop.id)
モデルの作成
ここではモデルの作成について説明します。
詳細は下記を参照してください。
https://peewee.readthedocs.org/en/latest/peewee/models.html
列の型
先の例のようにDateField、CharFieldをModelクラスに指定することでフィールドを設定できます。
ここで使用できるフィールどは下記の通りになります。
| Field Type |
Sqlite |
Postgresql |
MySQL |
| CharField |
varchar |
varchar |
varchar |
| TextField |
text |
text |
longtext |
| DateTimeField |
datetime |
timestamp |
datetime |
| IntegerField |
integer |
integer |
integer |
| BooleanField |
smallint |
boolean |
bool |
| FloatField |
real |
real |
real |
| DoubleField |
real |
double precision |
double precision |
| BigIntegerField |
integer |
bigint |
bigint |
| DecimalField |
decimal |
numeric |
numeric |
| PrimaryKeyField |
integer |
serial |
integer |
| ForeignKeyField |
integer |
integer |
integer |
| DateField |
date |
date |
date |
| TimeField |
time |
time |
time |
| BlobField |
blob |
bytea |
blob |
| UUIDField |
not supported |
uuid |
not supported |
field作成時のパラメータにより、デフォルト値の指定や重複の有無を指定できます。
詳細は下記を参照してください。
https://peewee.readthedocs.org/en/latest/peewee/api.html#fields
主キーの指定
peeweeで主キーを指定する方法について以下で説明します。
主キーを設定しない場合
PrimaryKeyを明示していない場合は、自動インクリメントのidという主キーを作成します。
class Test1(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
作成されるSQLiteのデータベース
CREATE TABLE IF NOT EXISTS "test1" ("id" INTEGER NOT NULL PRIMARY KEY, "name" VARCHAR(255) NOT NULL, "birthday" DATE NOT NULL, "is_relative" INTEGER NOT NULL
特定のフィールドを主キーに指定する場合
フィールドを作成する際にprimary_key=Trueと指定することで、該当のフィールドを主キーとします。
class Test2(Model):
name = CharField(primary_key=True)
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
作成されるSQLiteのデータベース
CREATE TABLE IF NOT EXISTS "test2" ("name" VARCHAR(255) NOT NULL PRIMARY KEY, "birthday" DATE NOT NULL, "is_relative" INTEGER NOT NULL)
複数のフィールドを主キーにする
CompositeKeyを用いることで複数のフィールドを主キーにできます。
class Test3(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
primary_key = CompositeKey('name', 'birthday')
作成されるSQLiteのデータベース
CREATE TABLE IF NOT EXISTS "test3" ("name" VARCHAR(255) NOT NULL, "birthday" DATE NOT NULL, "is_relative" INTEGER NOT NULL, PRIMARY KEY ("name", "birthday"))
インデックスの指定
peeweeでインデックスを指定する方法について以下で説明します。
指定の単一フィールドをインデックスにする
フィールドを作成する際、index=Trueとすることでインデックスにできます
class Test4(Model):
name = CharField(index=True)
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
作成されるインデックス
CREATE TABLE IF NOT EXISTS "test4" ("id" INTEGER NOT NULL PRIMARY KEY, "name" VARCHAR(255) NOT NULL, "birthday" DATE NOT NULL, "is_relative" INTEGER NOT NULL)
CREATE INDEX IF NOT EXISTS "test4_name" ON "test4" ("name")
指定のフィールドを組み合わせてインデックスにする
Meta クラスにてindexesを指定することで、複数のキーを組み合わせてインデックスを作成できます
class Test5(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
indexes = (
# 末尾に,がないとエラーになる
# 複数指定も可能
(('name', 'birthday'), False),
)
作成されるインデックス
CREATE TABLE IF NOT EXISTS "test5" ("id" INTEGER NOT NULL PRIMARY KEY, "name" VARCHAR(255) NOT NULL, "birthday" DATE NOT NULL, "is_relative" INTEGER NOT NULL)
CREATE INDEX IF NOT EXISTS "test5_name_birthday" ON "test5" ("name", "birthday")
重複を禁止するインデックスにする
フィールドを作成する際にunique=Trueを指定するか、Metaクラスのindexesの第二引数にTrueを指定することで重複を禁止するインデックスを作成できます。
class Test6(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
indexes = (
# 末尾に,がないとエラーになる
# 複数指定も可能
(('name', 'birthday'), True),
)
作成されるインデックス
CREATE TABLE IF NOT EXISTS "test6" ("id" INTEGER NOT NULL PRIMARY KEY, "name" VARCHAR(255) NOT NULL, "birthday" DATE NOT NULL, "is_relative" INTEGER NOT NULL)
CREATE UNIQUE INDEX IF NOT EXISTS "test6_name_birthday" ON "test6" ("name", "birthday")
外部キーについて
ForeignKeyField()を使用すると外部キーが指定できます。
to_field で主キー以外を指定できますが、このキーは主キーのいずれかであるか、一意制約を持つ必要があります。
http://peewee.readthedocs.org/en/latest/peewee/api.html#ForeignKeyField
様々なデータベースへの接続方法
peeweeでは様々なデータベースを使用できます。
詳細は下記を参照してください。
https://peewee.readthedocs.org/en/latest/peewee/database.html
SQLiteの接続例
memoryまたはファイルを指定して接続ができます。
from peewee import *
from datetime import date
db = SqliteDatabase(':memory:')
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
class Pet(Model):
owner = ForeignKeyField(Person, related_name='pets')
name = CharField()
animal_type = CharField()
class Meta:
database = db
db.create_tables([Person, Pet], True)
APSWの接続例
APSWについての詳細とインストール方法は下記を参照してください。
SQLiteが本気を出せるPythonのライブラリのAPSWを使用してみる
https://needtec.sakura.ne.jp/wod07672/?p=9243
下記でインストールできます。
pip install --user https://github.com/rogerbinns/apsw/releases/download/3.28.0-r1/apsw-3.28.0-r1.zip --global-option=fetch --global-option=--version --global-option=3.28.0 --global-option=--all --global-option=build --global-option=--enable-all-extensions
memoryまたはファイルを指定して接続ができます。
また、withを抜けるときにCommitが実行されるので最後のコミットはコメントアウトしてます(コメントアウトしないとエラーになる)
from peewee import *
from datetime import date
from playhouse.apsw_ext import APSWDatabase
from playhouse.apsw_ext import DateField
db = APSWDatabase('apswdatabase.sqlite')
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
class Pet(Model):
owner = ForeignKeyField(Person, related_name='pets')
name = CharField()
animal_type = CharField()
class Meta:
database = db
db.create_tables([Person, Pet])
# db.set_autocommit(False)
with db.transaction():
# birthday=date(1960, 1, 15) ...
uncle_bob = Person(name='Bob', birthday=date(1960, 1, 15), is_relative=True)
uncle_bob.save() # bob is now stored in the database
grandma = Person.create(name='Grandma', birthday=date(1960, 1, 5), is_relative=True)
herb = Person.create(name='Herb', birthday='1950-05-05', is_relative=False)
bob_kitty = Pet.create(owner=uncle_bob, name='Kitty', animal_type='cat')
herb_fido = Pet.create(owner=herb, name='Fido', animal_type='dog')
herb_mittens = Pet.create(owner=herb, name='Mittens', animal_type='cat')
herb_mittens_jr = Pet.create(owner=herb, name='Mittens Jr', animal_type='cat')
herb_mittens.delete_instance()
print ("-----------------")
for person in Person.select():
print (person.name, person.is_relative)
print ("-----------------")
query = Pet.select().where(Pet.animal_type == 'cat')
for pet in query:
print (pet.name, pet.owner.name)
print ("-----------------")
query = (Pet
.select(Pet, Person)
.join(Person)
.where(Pet.animal_type == 'cat'))
for pet in query:
print (pet.name, pet.owner.name)
#db.commit() # Not required for APSWDatabase
MySQLの接続例
データベース、ユーザー、パスワード、ホスト、ポートを指定して接続できます。
from peewee import *
from datetime import date
db = MySQLDatabase(
database='testdb',
user='test',
password="test",
host="192.168.80.131",
port=3306)
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db # This model uses the "people.db" database.
class Pet(Model):
owner = ForeignKeyField(Person, related_name='pets')
name = CharField()
animal_type = CharField()
class Meta:
database = db # this model uses the people database
db.create_tables([Person, Pet])
接続エラーが出る場合
下記のエラーが発生する場合はmysqlのドライバーをインストールしてください。
peewee.ImproperlyConfigured: MySQL driver not installed!
インストールの例:
pip3 install mysqlclient
https://github.com/coleifer/peewee/issues/1569
もしwindowsを使用していてエラーが出る場合は下記を参照。
https://stackoverflow.com/questions/51294268/pip-install-mysqlclient-returns-fatal-error-c1083-cannot-open-file-mysql-h
環境に応じたwhlファイルをダウンロードしてpip installでそのファイルを指定する。
Postgresの接続例
データベース、ユーザー、パスワード、ホスト、ポートを指定して接続できます。
from peewee import *
from datetime import date
from playhouse.postgres_ext import PostgresqlExtDatabase
# peeweeではデフォルトでhstoreという機能を使うようになっている。
db = PostgresqlExtDatabase(
database='peewee_test',
user='postgres',
password="",
host="192.168.80.131",
port=5432,
register_hstore=False)
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db # This model uses the "people.db" database.
class Pet(Model):
owner = ForeignKeyField(Person, related_name='pets')
name = CharField()
animal_type = CharField()
class Meta:
database = db # this model uses the people database
db.create_tables([Person, Pet])
接続エラーの場合
ERROR: Could not find a version that satisfies the requirement psqlclient (from versions: none)
ERROR: No matching distribution found for psqlclient
psycopg2をインストールする
pip install psycopg2
SpatiaLiteSQLへの接続方法
空間情報を扱うSQLiteの拡張であるSpatiaLiteへの接続について説明します。
http://qiita.com/mima_ita/items/64f6c2b8bb47c4b5b391
これにはplayhouse.sqlite_extのSqliteExtDatabaseを使用して次のように行います。
import os
from peewee import *
from playhouse.sqlite_ext import SqliteExtDatabase
# mod_spatialiteのあるフォルダをPATHに加える
os.environ["PATH"] = os.environ["PATH"] + ';C:\\tool\\spatialite\\mod_spatialite-NG-win-x86'
db = SqliteExtDatabase('testspatialite.sqlite')
class PolygonField(Field):
db_field = 'polygon'
db.field_overrides = {'polygon': 'POLYGON'}
# mod_spatialiteの読み込み
db.load_extension('mod_spatialite.dll')
class GeometryTable(Model):
pk_uid = PrimaryKeyField()
n03_001 = CharField()
n03_002 = CharField()
n03_003 = CharField()
n03_004 = CharField()
n03_007 = CharField()
Geometry = PolygonField()
class Meta:
database = db
for r in GeometryTable.select(GeometryTable.n03_001 , SQL('AsText(Geometry)').alias('Geo')).limit(10):
print (r.n03_001, r.Geo)
ポイントは以下の通りです。
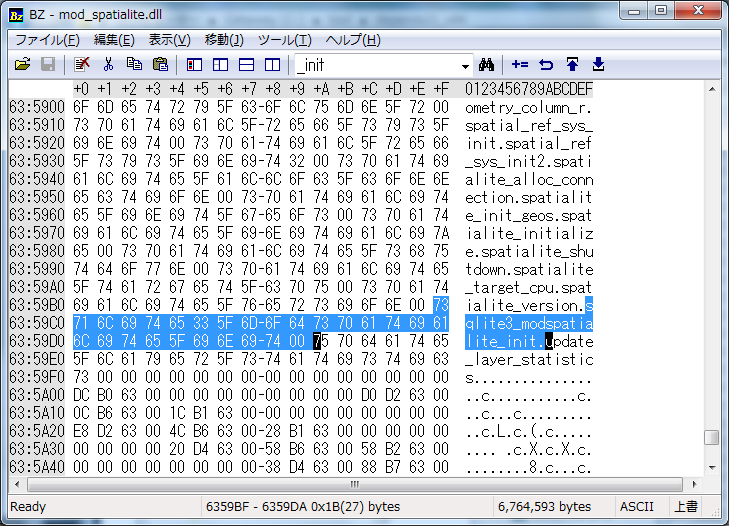
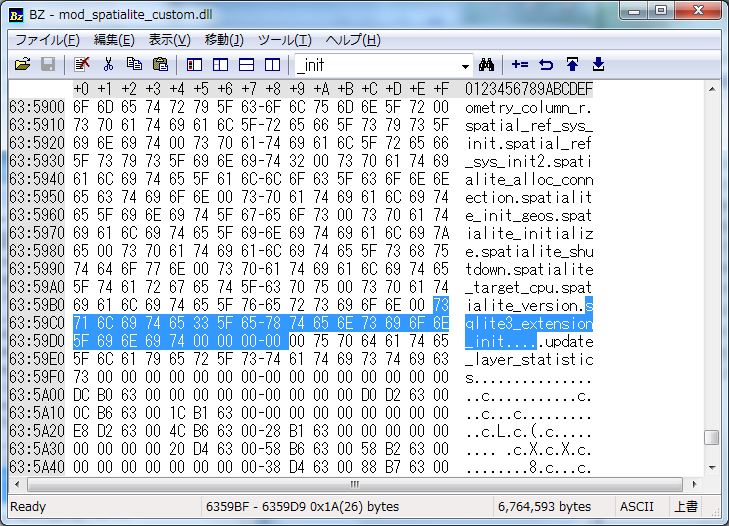
・load_extensionを使用してmod_spatialite.dll/soを呼び出す。
・POINTやPOLYGONといったspatialiteの列はFieldクラスを継承して定義しておき、db.field_overrides でコードで指定したdb_fieldとDBの型名を対応付ける
・AsTextなどのspatialite固有の関数はR()を用いて利用する
なお、RTreeIndexのテーブルにアクセスすると下記のようなエラーが出ます。
TypeError: 'idx_Station_geometry' object does not support indexing
この場合は、直接SQL実行してください。(APSWDatabase使用してもダメだった)
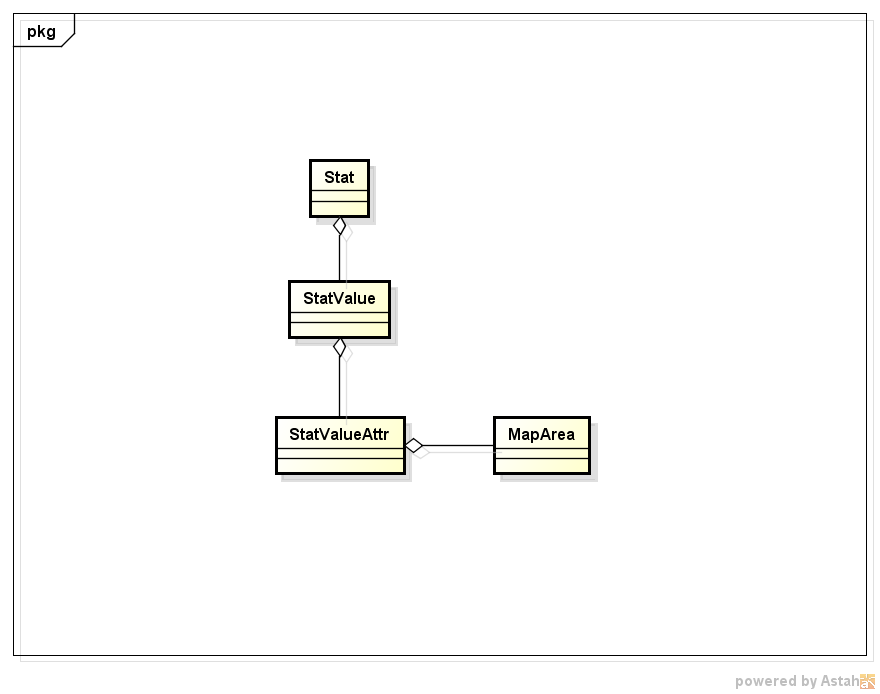
rows = database_proxy.connection().execute("""
SELECT
statValue.value,
AsGeoJson(MapArea.Geometry)
FROM
MapArea
inner join idx_MapArea_Geometry ON pkid = MapArea.id AND xmin > ? AND ymin > ? AND xmax < ? AND ymax < ?
inner join statValueAttr ON MapArea.stat_val_attr_id = statValueAttr.id
inner join statValueAttr AS b ON b.stat_value_id = statValueAttr.stat_value_id AND b.attr_value = ?
inner join statValue ON statValue.id = b.stat_value_id
WHERE
MapArea.stat_id like ?;
""",(xmin, ymin, xmax, ymax, attr_value, stat_id_start_str + '%'))
実行時に接続先を選択する方法
いままでの方法では、実行時に接続先を指定することができません。
そこで、Proxy() を使用することで、後から、設定ファイルの情報に合わせた接続を作成することもできます。
from peewee import *
from datetime import date
database_proxy = Proxy() # Create a proxy for our db.
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = database_proxy
class Pet(Model):
owner = ForeignKeyField(Person, related_name='pets')
name = CharField()
animal_type = CharField()
class Meta:
database = database_proxy
# あとから実際のデータベースを指定できる
db = SqliteDatabase(':memory:', autocommit=False)
database_proxy.initialize(db)
db.create_tables([Person, Pet])
Read Slaves やコネクションプール
Databaseによっては、Read Slavesを指定して、読み取り専用のDBにアクセスするようにしたり、コネクションプールを用いて複数の接続を取り扱うことも可能です。
https://peewee.readthedocs.org/en/latest/peewee/database.html#read-slaves
https://peewee.readthedocs.org/en/latest/peewee/database.html#connection-pooling
スキーマーのマイグレーション
Peeweeではスキーマの移行がサポートされています。
他のスキーマー移行ツールとことなり、バージョン管理は行っていませんが、移行を行うためのヘルパー関数が提供されています。
from peewee import *
from datetime import date
from playhouse.migrate import *
db = SqliteDatabase('mig.sqlite')
## 元のDBの作成
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = db
db.create_tables([Person])
data_source = [
{'name' : 'test1' , 'birthday' : date(1960, 1, 15), 'is_relative' : True},
{'name' : 'test2' , 'birthday' : date(1960, 2, 15), 'is_relative' : True},
{'name' : 'test3' , 'birthday' : date(1960, 3, 15), 'is_relative' : True},
{'name' : 'test4' , 'birthday' : date(1960, 4, 15), 'is_relative' : True},
{'name' : 'test5' , 'birthday' : date(1960, 5, 15), 'is_relative' : True},
{'name' : 'test1' , 'birthday' : date(1960, 1, 15), 'is_relative' : True},
]
Person.insert_many(data_source).execute()
## スキーマーの移行
migrator = SqliteMigrator(db)
title_field = CharField(default='')
status_field = IntegerField(null=True)
with db.transaction():
migrate(
migrator.add_column('Person', 'title', title_field),
migrator.add_column('Person', 'status', status_field),
migrator.drop_column('Person', 'is_relative'),
)
詳細は下記を参考にしてください。
https://peewee.readthedocs.org/en/latest/peewee/playhouse.html#migrate
既存のデータベースからオブジェクトを作成する方法
pwizを用いて既存のデータベースからオブジェクトを作成できます。
python -m pwiz --engine=sqlite mig.sqlite
このコマンドを実行することでpeople.dbからオブジェクトを標準出力します。
出力例
from peewee import *
database = SqliteDatabase('mig.sqlite')
class UnknownField(object):
def __init__(self, *_, **__): pass
class BaseModel(Model):
class Meta:
database = database
class Person(BaseModel):
birthday = DateField()
name = CharField()
status = IntegerField(null=True)
title = CharField()
class Meta:
table_name = 'person'
SQLのロギング
peeweeが発行したSQLをロギングするには以下の通りにします。
import logging
logger = logging.getLogger('peewee')
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.StreamHandler())
これによりpeeweeでSQLを発行するたびに次のようなログがstderrに出力されます。
('SELECT name FROM sqlite_master WHERE type = ? ORDER BY name;', ('table',))
('CREATE TABLE "test1" ("id" INTEGER NOT NULL PRIMARY KEY, "name" VARCHAR(255) NOT NULL, "birthday" DATE NOT NULL, "is_relative" SMALLINT NOT NULL)', [])
まとめ
以上のように、Peeweeを用いることでPythonから様々なDBの操作をSQLを記述せずに行えることが確認できました。