概要
LLMなどで作成されたテキストの品質を自動測定するのは難しい。
コサイン類似度やBLEUなどの手法があるが、それは人間の判断とは違いが多い。
G-EVALではタスクの導入と評価基準から評価手順をLLMで作成させた評価手順を用いてLLMに文章を評価させる。
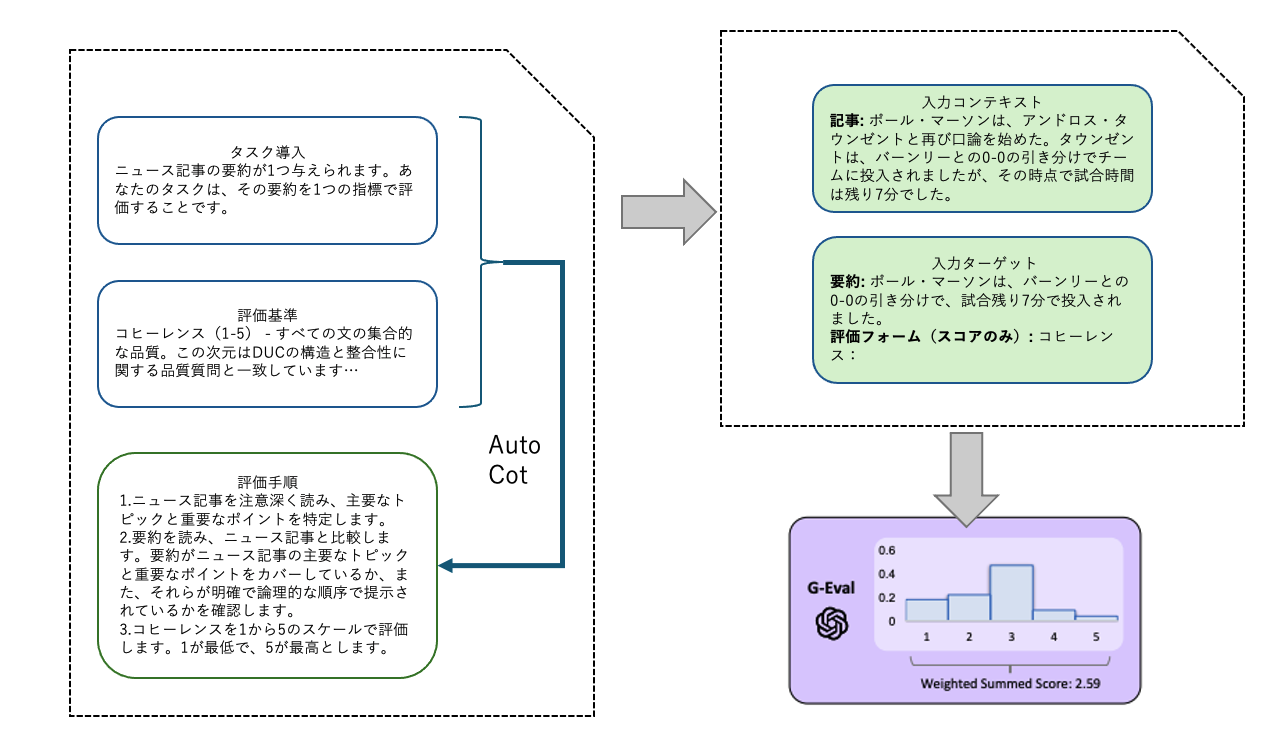
同じ評価手順で結果を複数回取得して、その評価結果からスコアを算出する
和訳したPDFまたは原文を参照。
G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment
https://arxiv.org/pdf/2303.16634
作者のGitHub
https://github.com/nlpyang/geval
メモ
AutoCotで評価手順を自動で生成すると論文にはあるが、GitHubのコードでそれを行なっている形跡は見えなかった。
もしかしてGitHubに用意してあるプロンプトがすでにAutoCotの結果かもしれないが、それをどう作ったかがいまいち読み取れなかった。
スコアリングについては以下のようにchatgptAPIを呼び出す際に同じプロンプトでnを指定して結果を複数回取得している。
https://github.com/nlpyang/geval/blob/main/gpt4_eval.py#L41
論文中では出力トークンの確率を使用してスコアを正規化し、それらの重み付き総和とあるが、実際は単純な平均に見える
https://github.com/nlpyang/geval/blob/main/meta_eval_summeval.py#L58
logprobsがコメントアウトしてあるので、途中でやめた?
https://github.com/nlpyang/geval/blob/main/gpt4_eval.py#L40
その後
「A Closer Look into Using Large Language Models for Automatic Evaluation」にG-EVALの評価の論文が書かれている。
https://aclanthology.org/2023.findings-emnlp.599/
- 自動Chain-of-Thought(CoT)を使用しない方が、特定の評価基準で人間の評価と高い相関を示すことがある
- LLMに単にスコアを出力させるのではなく、そのスコアに対する「理由の説明」を求めることで、人間の評価との相関を向上させる