はじめに
以下の記事でcamelotを使用してPDFからテーブルを抽出する場合に、PDFが点線で構成されているとテーブルを旨く認識できない問題を上げました。
・camelotで点線を実線として処理する
この時はcamelotが保持する中間の画像データに対してOpenCVを使用して点線を実線に書き換えるアプローチをとりました。
今回はPDFに含まれている線情報を、そもそも書き換えることができるかを検証してみます。
PDFのコンテンツの情報を取得する
camelotをインストールする際に同時にインストールされるPyPDF2を使用して解析してみます。
PyPDF2にはextractTextというPDF中からテキスト情報を抽出する処理がありますが、これを参考にすることでPDF中の線情報を取得できると考えられます。
以下のコードはextractTextを参考に記載したものでPDFからコンテンツ情報を列挙するものになります。
import PyPDF2
from PyPDF2.pdf import ContentStream
from PyPDF2.utils import b_
pdf = PyPDF2.PdfFileReader(open("Test.pdf", "rb"))
page = pdf.getPage(0)
content = page['/Contents'].getObject()
if not isinstance(content, ContentStream):
content = ContentStream(content, pdf)
for operands, operator in content.operations:
print(operator, operands)
PDFはoperatorとoperandsの組み合わせでテキストや画像を描画しており、その詳細の仕様は下記にあります。
https://www.adobe.com/content/dam/acom/en/devnet/acrobat/pdfs/PDF32000_2008.pdf
この資料の「A.2 PDF Content Stream Operators」を元にoperatorがどんな動きをしているか解析することが可能になります。
camelotで点線を実線として処理するにて実験に使用したPDFファイルは以下のoeratorが使用されていることがわかります。
b're' [116.3, 596.38, 374.11, 1.92]これの意味は以下のようになります。
| Operator | Operands | Description | 解説ページ |
|---|---|---|---|
| re | x y width height | Append rectangle to path | 133 |
これで四角形の座標と大きさを認識することができます。
PDFのコンテンツの情報を更新する
PDFの図形情報を書き換えるのは、簡単にいきそうもありませんでした。
しかしながら、reportlabを使用することで図形を追加することはできそうです。
具体的な手順は以下のようになります。
- 入力のPDFを開いて図形の座標を取得する。
- reportlabを使用してキャンバスに取得した図形と同じ箇所に、同じ図形を描画して新しいPDFのページを作る
- 入力につかったページと新規のページをマージして出力する。
これを実装したものが以下のようになります。
import PyPDF2
from PyPDF2 import PdfFileWriter, PdfFileReader
from io import BytesIO
from reportlab.pdfgen import canvas
from PyPDF2.pdf import ContentStream
from PyPDF2.utils import b_
def get_rectangle(content):
result = []
for operands, operator in content.operations:
if operator == b_('re'):
result.append(operands)
return result
with open('output.pdf', 'wb') as output_stream, open("Test.pdf", "rb") as input_stream:
output = PdfFileWriter()
# read your existing PDF
input_pdf = PyPDF2.PdfFileReader(input_stream)
for page in range(input_pdf.numPages):
print(page + 1, '/', input_pdf.numPages)
page_obj = input_pdf.getPage(page)
content = page_obj['/Contents'].getObject()
if not isinstance(content, ContentStream):
content = ContentStream(content, input_pdf)
rectangles = get_rectangle(content)
#
buffer = BytesIO()
c = canvas.Canvas(buffer, pagesize=(page_obj.mediaBox.getWidth(), page_obj.mediaBox.getHeight()))
c.setStrokeColorRGB(255, 0, 0)
for rect in rectangles:
c.rect(rect[0], rect[1], rect[2], rect[3], fill=0)
c.showPage()
c.save()
buffer.seek(0)
### DEBUG
#pdf_tmp = buffer.getvalue()
#open('tmp{}.pdf'.format(page), 'wb').write(pdf_tmp)
###
new_pdf = PdfFileReader(buffer)
page_obj.mergePage(new_pdf.getPage(0))
output.addPage(page_obj)
output.write(output_stream)変換結果:
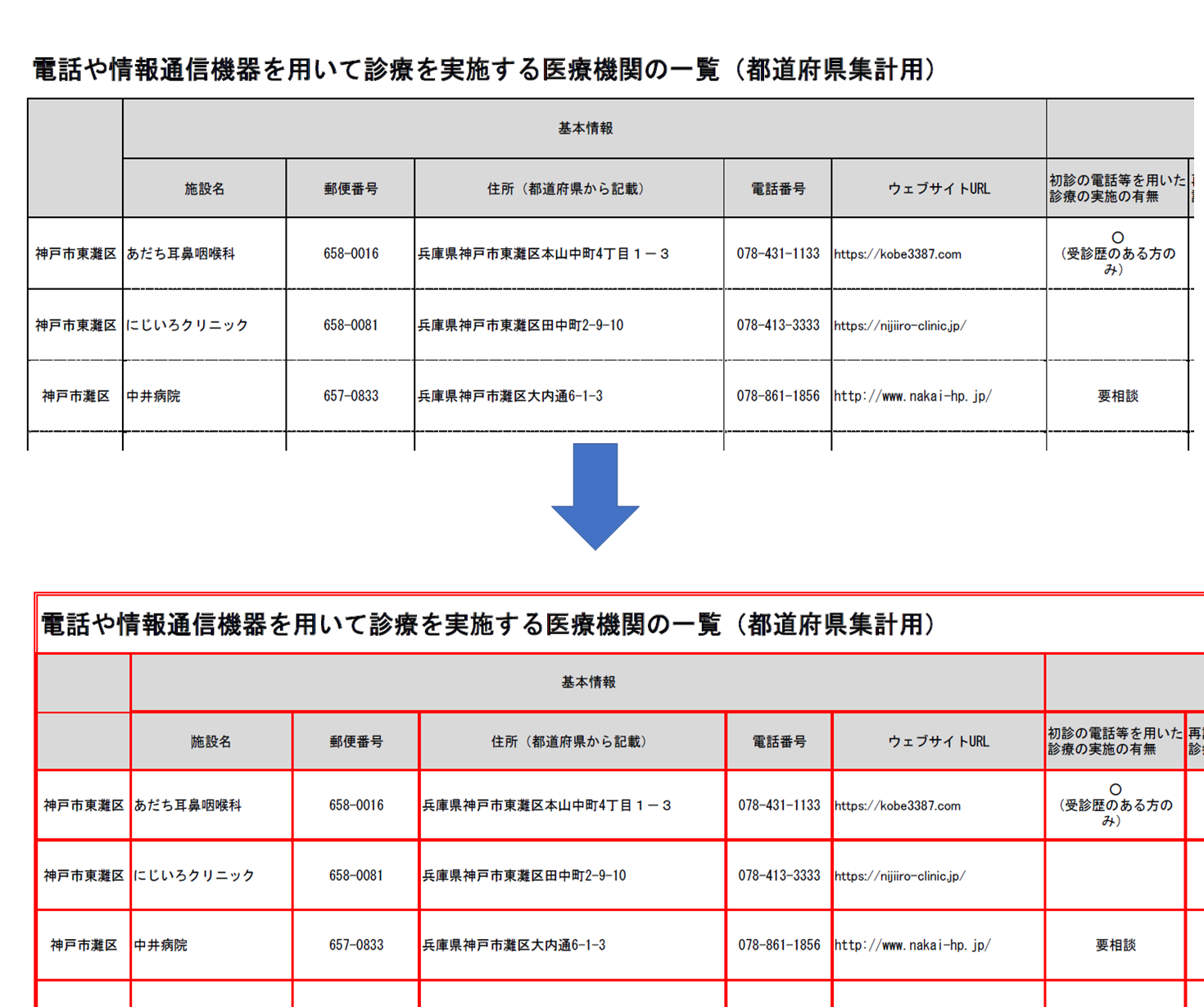
画像のリンク
Excelの罫線のないところも線を描画していますが、camelotで認識するという目的では使用できると思います。
問題点
このアプローチでは大きな問題点が2点あります。
まず、ファイルサイズが激増します。3MBのPDFが440MBになりました。
また、ファイルの増加と関係すると思いますが使用メモリも大量になります。700MBほど使用していました。
この問題はIssueとしてあがっていますが、解決はしていません。
StackOverflowでもファイルサイズの問題は質問されていますが、別ツールを使用しろという結果になっています。
オープンソースのcpdfsqueezeを使用することでファイルのサイズの問題は解決できますが、処理中のメモリの問題は依然として残る結果となります。
下記のページでは代替のライブラリであるPyMuPdf libraryが紹介されています。
まとめ
PDF中の点線を実線に書き換えるというアプローチは、PDF上のreオペレータを見ることで場所を特定して、線を上書きするという方法で可能です。
この場合、Excelの罫線のないところも線が引かれてしまうので、これを回避するには別のoperatorも観る必要があります。
また、PyPDF2を使用した場合、圧縮がサポートされていないためファイルサイズが増加し、また、処理中のメモリも大きなものとなりまします。
ファイルサイズの増加については外部のツールで圧縮することが可能ですが、メモリの増加についてはPyPDF2上で回避する方法は現時点でなさそうです。
[…] PDFの点線を実線におきかえる(PyPDF2 + reportlab) […]