草津市都市計画交通政策課では草津市のコミュニティバス「まめバス」のオープンデータ化を行っています。
http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.html
ここでは、この「まめバス」のデータを取り扱ってみます。
目的としては、自動で、全てのデータをダウンロードして、適切にDataBaseを構築してバスデータがWebで使用できるようにします。
この際、Excelデータは、Windowsだけでなく、Linuxでも解析するものとします。
これにより、多くのレンタルサーバーなどで、(一定の変更の範囲内では)人手を介さず自動で、最新のデータを使用できることになります。
デモ
http://needtec.sakura.ne.jp/bus_data/kusatu.html
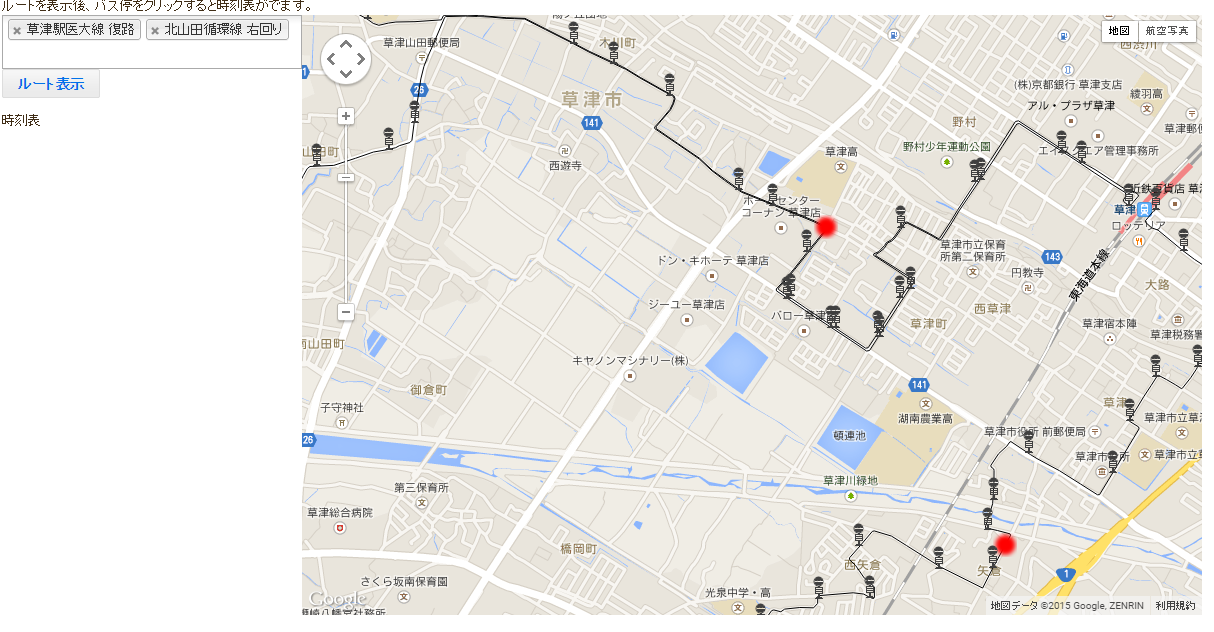
Github
https://github.com/mima3/bus_data
以下のコマンドでデータをダウンロードしてDBの構築は行います。
python import.py application.iniデータが更新された場合も、このコマンドで最新を取り込むことができます。cronなどで定期的に実行するといいでしょう。
データの説明
各路線は以下の3つの構成でなりたっています。
| 名称 | 形式 | 説明 |
|---|---|---|
| 時刻表 | Excel | 各バス亭の到着時刻を記述したデータです。 平日、土曜日と曜日により到着時刻がことなる場合があります |
| 停留所 | csv | 停留所の名前、読み、座標が格納されたCSVデータです。 同一路線において右回り、左回りと複数データが存在する可能性があります。 |
| 路線図 | shape | 路線図の形状を表したshapeファイルです。この測地系は「平面直角2000(6系)」であることに注意してください。 同一路線において右回り、左回りと複数データが存在する可能性があります。 |
データを取り扱う際に注意する点がいくつか存在します。
同じバス停名で複数のバス停が存在する。
同名のバス停が複数存在します。
たとえば、M04_stops_ccw.csvを見てください。
野村運動公園口が2行存在します。
135.954709,35.023382に存在する野村運動公園口と、135.954445,35.023323に存在する野村運動公園口です。
同じ位置のバスは同じルートで複数回停車する
同じ位置のバス停であっても、同じルートで複数回停車する場合があります。
たとえば、M04_stops_ccw.csvを見てください。
草津駅西口は、1番目と37番目に停車します。
停車順番はCSVの2列目に記載されています。
CSVとExcelの表記のゆれ
ExcelとCSVでバス停名が異なる場合があります。
改行が入っているとか、半角・全角の違いどころか、名称が違うものがいくつかあります。
| csv | excel |
|---|---|
| 山田小学校前 | 山田小学校 |
| 木ノ川東 | 木川東 |
| 西渋川1丁目 | 西渋川一丁目 |
| 野村八丁目 | 野村8丁目 |
| 新堂中学校前 | 新堂中学校 |
時刻表の曜日の表し方の不統一
普通、Excelのデータの配置は同じようになるもんですが、ワークブック毎に異なっています。
M01_stop_times.xlsxを見てみましょう。
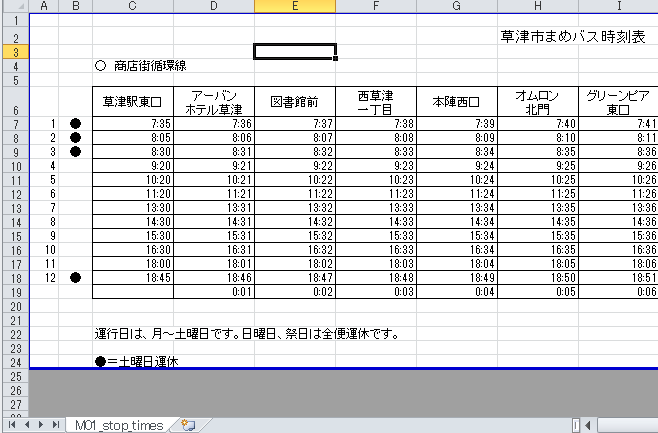
このワークブックでは「●」の有無で土曜日か、平日かを判断しています。
しかし、別のM03_stop_times.xlsxを見てみましょう。
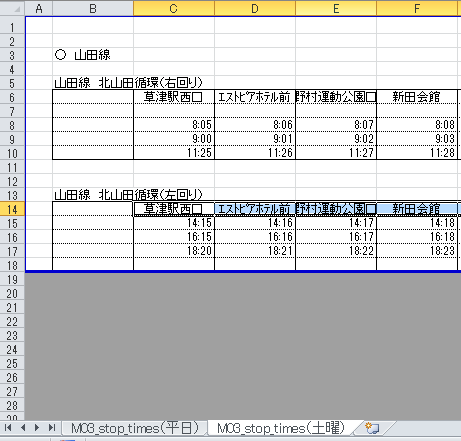
ここではシート毎に曜日を分けています。
| ブック名 | 曜日の判定方法 |
|---|---|
| M01_stop_times.xlsx | ●による判定 |
| M02_stop_times.xlsx | ●による判定 |
| M03_stop_times.xlsx | シート分割 |
| M04_stop_times.xlsx | シート分割 |
| M05_stop_times.xlsx | 曜日についての言及なし |
このことから察することができると思いますが、データ開始位置はブックごとに違うと見なしたほうがいいでしょう。
バス停名と時刻の間の空行
バス停名の次行から時刻が入っているので、そこから検索していき、1行すべてがブランクだったら時刻表が終わったと判定したくなるかと思います。
しかしながら、それはできません。
M04_stop_times.xlsxの山田線(木ノ川循環:左回り)を見てみましょう。
バス停名の次行まるまる空白で、その次の行からデータが始まっています。
拡張性のないデータの配置
以下のシートの場合、バスの本数が増えても単純にデータ量が変わるだけなので、Excelを解析する処理に変更はありません。
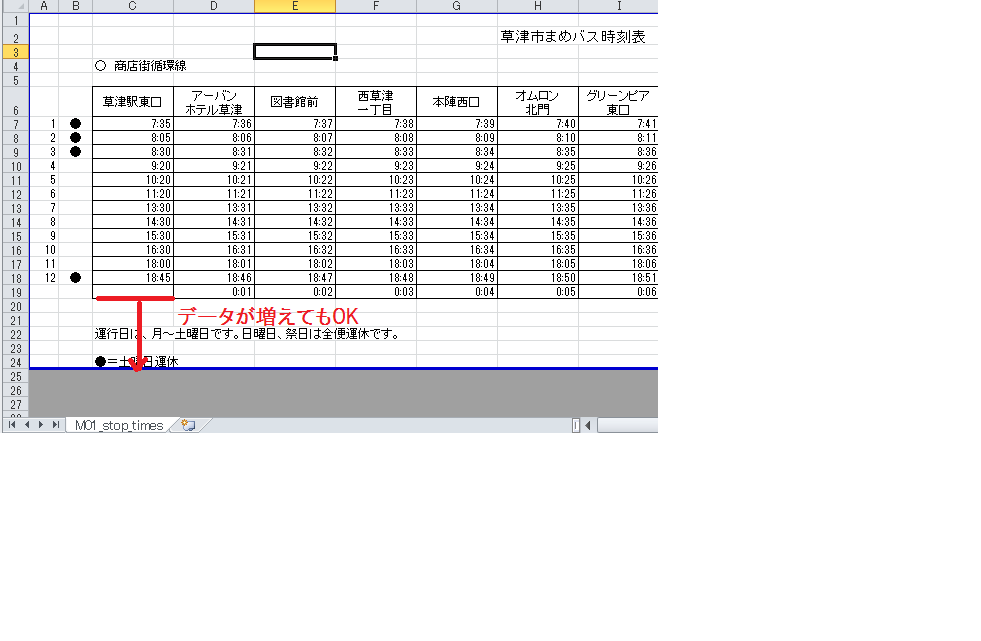
しかし、次の行を考えてみましょう。
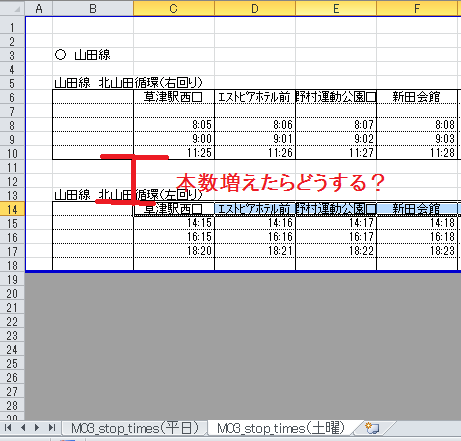
この例だと、データ量が増えると下部のデータ開始位置もずれるため、処理を変更する必要がでてきます。
Pythonで取り扱う例
Excelファイルを取り扱う
PythonでExcelを取り扱うには、xlrdを使用します。
https://github.com/python-excel/xlrd
いくつか、このライブラリを使用したサンプルがググると出てきますが、基本的に、公式のサンプルコードを参考に作成した方がいいでしょう。
https://github.com/python-excel/xlrd/blob/master/scripts/runxlrd.py
たとえば、以下のような実装例がよくあります。
from xlrd import open_workbook
wb = open_workbook('test_err.xlsx')
for sh in wb.sheets():
for row in range(sh.nrows):
values = []
for col in range(sh.ncols):
v = sh.cell(row,col).value
if not isinstance(v, basestring):
v = str(v)
v = v + ':' + str(sh.cell(row,col).ctype)
values.append(v)
print ','.join(values)XLS拡張子や、セルの結合のないxlsxでは上記のコードは何の問題もなく動作します。
しかし、以下のようなセルの結合があるシートを操作するとエラーになります。
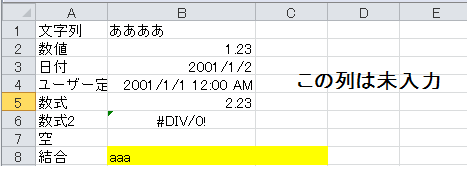
エラー内容
Traceback (most recent call last):
File "test2.py", line 7, in <module>
v = sh.cell(row,col).value
File "C:\Python27\lib\site-packages\xlrd-0.9.3-py2.7.egg\xlrd\sheet.py", line
399, in cell
self._cell_types[rowx][colx],
IndexError: array index out of rangeどうも、行によって列の数がことなっており、行ごとに列数を取得する必要があります。
以下のようにrow_lenで行毎に列数を取得すれば、この問題は回避できます。
from xlrd import open_workbook
wb = open_workbook('test_err.xlsx')
for sh in wb.sheets():
for row in range(sh.nrows):
values = []
for col in range(sh.row_len(row)):
v = sh.cell(row,col).value
if not isinstance(v, basestring):
v = str(v)
v = v + ':' + str(sh.cell(row,col).ctype)
values.append(v)
print ','.join(values)
このほか、日付表示の方法についても、runxlrd.pyでは実装しているので、とりあえず一度は読んだ方がいいでしょう。
どうデータを取り込むか
先に述べたように、気分でExcelを作っている節があるので、それぞれに柔軟に対応する必要があります。
そこで、どのようにデータを取り込むかをJSONの設定ファイルに保存しておき、それをみてデータを取り込むようにしました。
https://github.com/mima3/bus_data/blob/master/data/kusatu.json
ダウンロード後の処理の分岐
今回は圧縮済みのデータと、圧縮していないデータが混ざっています。
そこで、設定ファイルのdownloadにてダウンロード後の処理を記載しています。
data/kusatu.json
"download" : {
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_stop_times.xlsx" : "save_local",
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_stops_ccw.csv" : "save_local",
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_shapes.zip" : "expand_zip",save_localはローカルディスクに保存する。
expand_zipは保存後解凍を試みる処理を実行します。
実際のコードは下記を参照してください。
https://github.com/mima3/bus_data/blob/master/downloader.py
CSVとEXCELの表記の揺れに対応
CSVとExcelの表記のゆれに対応します。
基本的なルールは以下の通りです。
・バス亭名を設定ファイルのconvert_ruleに合わせて変換する
・改行を取りのぞく
・半角を全角にする。
バス停名の変換
data/kusatu.json
"convert_rule" : {
"山田小学校前": "山田小学校",
"木ノ川東":"木川東",
"西渋川1丁目": "西渋川一丁目",
"野村八丁目": "野村8丁目",
"新堂中学校前": "新堂中学校"
},bus_data_parser.py
def convert_bus_stop_name(rule, bus_stops):
for bus_stop in bus_stops:
if bus_stop['stopName'] in rule:
bus_stop['stopName'] = rule[bus_stop['stopName']改行の除去・半角を全角にする
bus_data_parser.py
def get_bus_timetable(wbname, sheetname, stop_offset_row, stop_offset_col, stopdirection, timetable_offset_row, timetable_offset_col, chk_func):
xls = xlsReader(wbname, sheetname)
stop_name_list = []
if stopdirection == DataDirection.row:
busdirection = DataDirection.col
else:
busdirection = DataDirection.row
xls.set_offset(stop_offset_row, stop_offset_col)
while True:
v = xls.get_cell()
if not v:
break
v = zenhan.h2z(v)
v = v.replace('\n', '')
stop_name_list.append(v)
xls.next_cell(stopdirection)半角、全角の変換にはzenhanを利用しています。
https://pypi.python.org/pypi/zenhan
CSV、EXCEL、Shapeファイルのインポートルールの記述
各ファイルをどのようにインポートするかを以下のように指定します。
"import_rule" : [
{
"operation_company" : "草津市",
"line_name" : "商店街循環線",
"shape" : "M01_shapes/M01.shp",
"srid" : 2448 ,
"timetables" : [
{
"route" : "Route1L",
"routeName" : "商店街循環線",
"bus_stops" : "M01_stops_ccw.csv",
"weekday_timetable" : {
"workbook" : "M01_stop_times.xlsx",
"sheetname" : "M01_stop_times",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M01_stop_times.xlsx",
"sheetname" : "M01_stop_times",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3,
"check_func" : "check_shoutengai_saturday"
},
"holyday_timetable" : {
}
}
]
}, // 略
{
"operation_company" : "草津市",
"line_name" : "山田線(北山田循環)",
"shape" : "M03_shapes/M03.shp",
"srid" : 2448 ,
"timetables" : [
{
"route" : "Route3R",
"routeName" : "北山田循環線 右回り",
"bus_stops" : "M03_stops_cw.csv",
"weekday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_times(平日)",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_times(土曜)",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"holyday_timetable" : {
}
},
{
"route" : "Route3L",
"routeName" : "北山田循環線 左回り",
"bus_stops" : "M03_stops_ccw.csv",
"weekday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_times(平日)",
"stop_offset_row" : 14,
"stop_offset_col" : 3,
"timetable_offset_row" : 15,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_times(土曜)",
"stop_offset_row" : 14,
"stop_offset_col" : 3,
"timetable_offset_row" : 15,
"timetable_offset_col" : 3
},
"holyday_timetable" : {
}
}
]
}, // 略shapeファイルに関係するのは「shape」と「srid」です。
shapeにはshapeファイル名、sridには測地系を記述します。
csvファイルに関係するのは「bus_stops」です。
bus_stopsにはCSVファイル名を記述します。
Excelファイルは、平日、土曜日、休日毎に記載します。
workbookにワークブック名
sheetnameにシート名
stop_offset_row、stop_offset_colにバス停名が記載される開始位置、
timetable_offset_row、timetable_offset_colに時刻が記載される開始位置を記載します。
check_funcは省略可能な項目で、時刻表を1行読み込むたびに実行されるコールバック関数を指定します。
ここでは、下記のように特定の列の値をチェックして、無効なデータであれば、Falseを返し行を無視します。これは土曜日の判定に使用しています。
import.py
class BusParserCallBack(object):
def check_shoutengai_saturday(self, workbook, sheet, busrow, buscol, item):
if sheet.cell(busrow - 1, 2 - 1).value:
return True
else:
return False
Shapeファイルの取り扱い
Pythonの場合は、pyshpを使うといいでしょう。
下記を参考にしてください。
Pythonで国土数値情報のShapeFileを操作してデータベースにインポートしてみる
http://qiita.com/mima_ita/items/e614a281807970427921
測地系の変換
まめバスのshapeファイルの測地系は「平面直角2000(6系)」であり、SRIDだと、2448になります。
これを、世界測地系に変換しなければなりません。
この変換は結構めんどくさいのですが、SpatiaLiteなどのジオメトリを扱うDBだと、簡単に対応できます。
Spatialiteの場合は次のようなSQLを実行すると、返還ができます。
select AsText(Transform(GeomFromText('POINT(-4408.916645 -108767.765479)', 2448), 4326))pythonのコードでは次のようになります。
bus_db.py
for timetable in timetables:
database_proxy.get_conn().execute(
"""
INSERT INTO RouteTable
(metaData_id, operationCompany, lineName, route, routeName, geometry)
VALUES(?, ?,?,?,?,Transform(GeometryFromText(?, ?),?))
""",
(
meta_id,
operation_company,
line_name,
timetable['route'],
timetable['routeName'],
routedict[timetable['route']], src_srid, SRID
)
)まとめ
このように、Pythonのライブラリを使えば特に意識しなくても「まめバス」のデータを使用することはできます。
ただし、データにかなり癖があり、機械解析を前提するような構成になっていないので、そこで苦労するでしょう。
もし、機械でデータを取り扱いやすくデータ側を改善するなら以下の点が必要だと思います。
・CSV,Excelなどの別ファイル間のデータの整合性をとる
・Excelを使うのはしょうがないとして書式は統一させる
・データが増えたときの考慮をおこなう。